
Was ist robots.txt?
Eine robots.txt ist eine Textdatei mit Anweisungen für Suchmaschinen-Robots, die diesen mitteilt, welche Seiten sie crawlen können und welche nicht.
Diese Anweisungen werden durch „Erlauben“ oder „Verbieten“ des Zugriffs durch bestimmte oder alle Bots spezifiziert.
So sieht eine robots.txt-Datei aus:
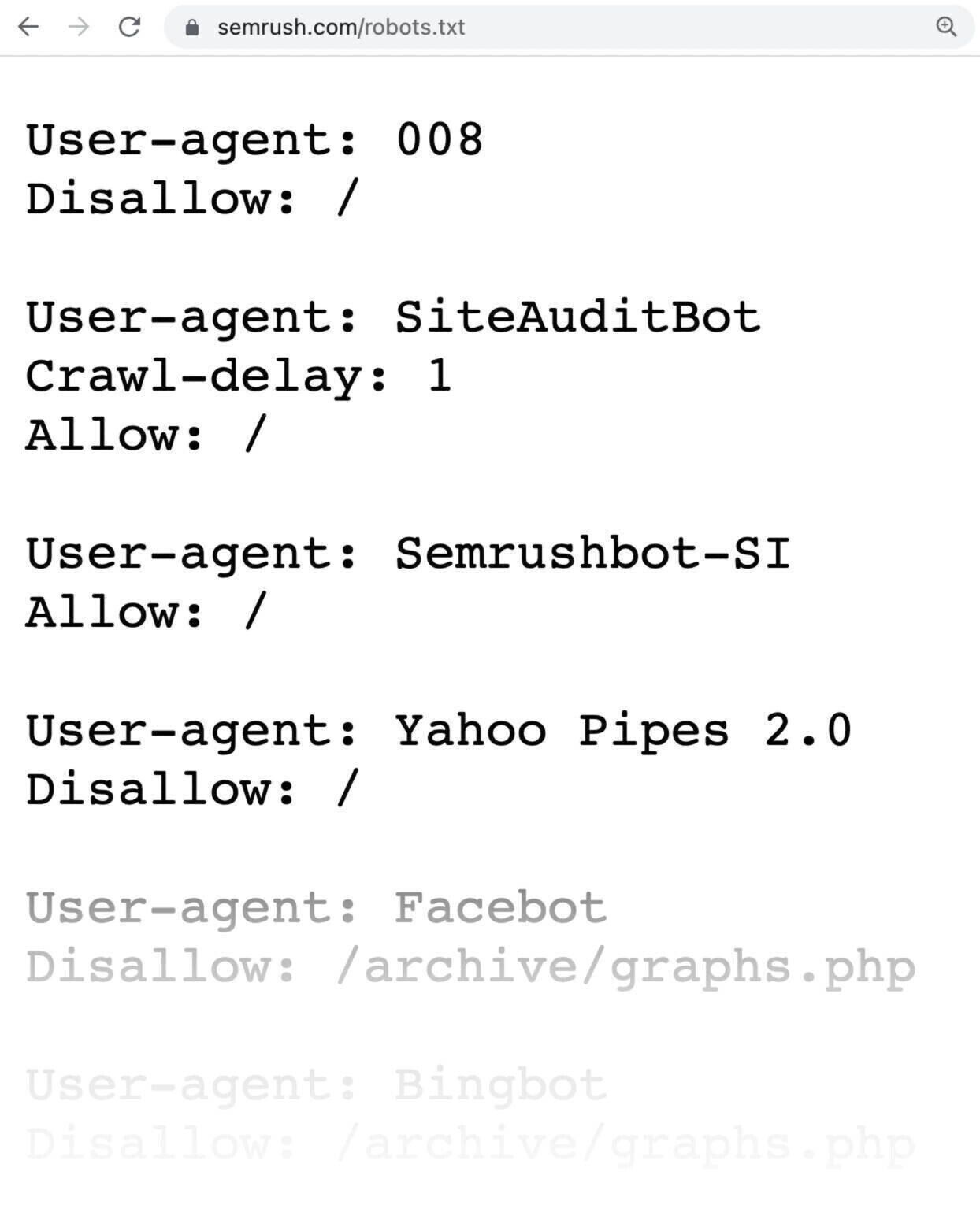
Robots.txt-Dateien sehen kompliziert aus, aber ihre Syntax (Computersprache) ist recht einfach. Wir gehen weiter unten auf die Details ein.
In diesem Artikel erklären wir:
- Warum robots.txt-Dateien wichtig sind
- Wie robots.txt-Dateien funktionieren
- Wie du eine robots.txt-Datei erstellst
- Welche Best Practices du bei deiner robots.txt befolgen solltest
Warum ist die robots.txt wichtig?
Eine robots.txt-Datei hilft bei der Verwaltung von Webcrawler-Aktivitäten, sodass diese nicht zu viele Abrufe generieren und keine Seiten indexieren, die nicht für die Öffentlichkeit bestimmt sind.
Hier sind einige wichtige Zwecke, für die du eine robots.txt-Datei nutzen kannst:
1. Dein Crawl-Budget optimieren
Das „Crawl-Budget“ ist die Anzahl der Seiten, die Google pro Besuch auf deiner Website crawlt. Dies kann je nach Größe, Zustand und Backlinks deiner Website variieren.
Das Crawl-Budget ist wichtig, denn wenn die Anzahl deiner Seiten dein Crawl-Budget übersteigt, werden nicht alle deine Seiten indexiert.
Und die nicht indexierten Seiten werden dann auch nicht in der Suche gefunden.
Indem du unnötige Seiten mit der robots.txt-Datei blockierst, kannst du dafür sorgen, dass der Googlebot (der Web-Crawler von Google) mehr Crawl-Budget für relevante Seiten übrig hat.
2. Doppelte und nichtöffentliche Seiten ausschließen
Suchmaschinen müssen nicht unbedingt jede Seite deiner Website crawlen, denn nicht alle müssen in den Suchergebnissen auftauchen.
Beispiele für Seiten, die dort nichts zu suchen haben, sind Staging-Websites, interne Suchergebnisse, doppelte Seiten sowie Login-Seiten.
WordPress zum Beispiel unterbindet automatisch die Indexierung des Verzeichnisses /wp-admin/ durch Webcrawler.
Diese Seiten müssen existieren, aber sie müssen nicht indexiert und in Suchmaschinen gelistet werden. Der Ausschluss dieser Seiten vom Crawling ist ein Paradebeispiel für die Nutzung von robots.txt.
3. Ressourcen verbergen
Manchmal ist es sinnvoll, Ressourcen wie PDFs, Videos und Bilder aus den Suchergebnissen auszuschließen.
Gründe dafür können sein, dass diese Ressourcen privat sind oder dass sich Google auf wichtigere Inhalte konzentrieren soll.
Die Verwendung von robots.txt ist dann der beste Weg, um zu verhindern, dass diese Dateien indexiert werden.
Wie funktioniert eine robots.txt-Datei?
Robots.txt-Dateien teilen Suchmaschinen-Bots mit, welche URLs sie crawlen können und – noch wichtiger – welche nicht.
Suchmaschinen haben zwei Hauptaufgaben:
- Das Web durchsuchen, um Inhalte aufzuspüren
- Inhalte indexieren, damit sie Suchenden angezeigt werden können
Während Suchmaschinen-Bots das Netz durchsuchen, finden sie Links und folgen ihnen. Dieser Prozess führt sie über Milliarden von Links von Website A zu Website B zu Website C.
Bei der Ankunft auf einer Website sucht ein Bot als Erstes nach einer robots.txt-Datei.
Wenn er eine findet, liest er den Inhalt aus, bevor er weitere Seiten abruft.
Wie erwähnt, sieht eine robots.txt-Datei etwa so aus:

Die Syntax ist sehr einfach.
Sie weist Bots Regeln zu, indem sie den User-Agent (der Name des jeweiligen Bots) angibt, gefolgt von den betreffenden Anweisungen (oder Regeln).
Du kannst auch den Stern (*) als Platzhalter verwenden, um die darauf folgenden Anweisungen allen User-Agents zuzuweisen. Das heißt, die Regel gilt dann für alle Bots und nicht nur für einen bestimmten.
So würde die Anweisung beispielsweise aussehen, wenn du allen Bots außer DuckDuckGo erlauben möchtest, deine Website zu crawlen:

Hinweis: Eine robots.txt-Datei enthält Anweisungen, kann deren Befolgung aber nicht erzwingen. Es ist mehr wie ein Verhaltenskodex. Gute Bots (wie die der Suchmaschinen) befolgen die Regeln, zwielichtige Bots (wie Spam-Bots) ignorieren sie.
Wie du eine robots.txt-Datei findest
Die robots.txt-Datei wird genau wie jede andere Datei deiner Website auf deinem Server gehostet.
Du kannst die robots.txt-Datei für jede beliebige Website anzeigen, indem du die vollständige URL der Homepage eingibst und dann /robots.txt hinzufügst, z. B. https://semrush.com/robots.txt.

Hinweis: Eine robots.txt-Datei sollte sich immer im Stammverzeichnis deiner Domain befinden. Für die Website www.beispiel.de befindet sie sich also unter www.beispiel.de/robots.txt. Sollte sich die Datei woanders verstecken, gehen die Crawler davon aus, dass keine vorhanden ist.
Bevor wir dir zeigen, wie man eine robots.txt-Datei erstellt, schauen wir uns die darin genutzte Syntax an.
Die Syntax einer robots.txt-Datei
Eine robots.txt-Datei besteht aus:
- einem oder mehreren Blöcken von „Anweisungen“ (Regeln);
- jeweils einer Angabe eines bestimmten „User-Agent“ (Suchmaschinen-Bot);
- und einer Anweisung „erlauben“ oder „nicht erlauben“.
Ein einfacher Anweisungsblock kann etwa so aussehen:
User-agent: Googlebot
Disallow: /nicht-fuer-google
User-agent: DuckDuckBot
Disallow: /nicht-fuer-duckduckgo
Sitemap: https://www.deinewebsite.de/sitemap.xmlDie Anweisung „User-Agent“
Die erste Zeile jedes Anweisungsblocks betrifft den „User-Agent“. Hier wird der angesprochene Crawler identifiziert.
Wenn du also beispielsweise den Googlebot anweisen möchtest, deine WordPress-Admin-Seite nicht zu crawlen, beginnt deine Anweisung mit:
User-agent: Googlebot
Disallow: /wp-admin/Beachte, dass die meisten Suchmaschinen mehrere Crawler haben, die für den normalen Index, Bilder, Videos usw. verantwortlich sind.
Suchmaschinen-Bots berücksichtigen immer den spezifischsten Block von Anweisungen, den sie finden können.
Angenommen, du hast drei Gruppen von Anweisungen: eine für *, eine für Googlebot und eine für Googlebot-Image.
Wenn nun der User-Agent Googlebot-News deine Website crawlt, befolgt er die Anweisungen für Googlebot.
Der User-Agent Googlebot-Image dagegen befolgt die spezifischeren Anweisungen für Googlebot-Image.
Hier findest du eine detaillierte Liste der Webcrawler und ihrer verschiedenen User-Agents.
Die Anweisung „Disallow“
Die zweite Zeile in jedem Anweisungsblock ist die „Disallow“-Zeile.
Hier kannst du mehrere Disallow-Anweisungen hinterlegen, die angeben, auf welche Teile deiner Website der Crawler nicht zugreifen soll.
Eine leere „Disallow“-Zeile bedeutet, dass du nichts verbietest – der Crawler kann dann also auf alle Bereiche deiner Website zugreifen.
Wenn du beispielsweise allen Suchmaschinen erlauben willst, deine gesamte Website zu crawlen, würde dein Block wie folgt aussehen:
User-agent: *
Allow: /Wenn du im Gegenteil alle Suchmaschinen daran hindern möchtest, deine Website zu crawlen, würde der Block so aussehen:
User-agent: *
Disallow: /Bei Anweisungen wie „Allow“ und „Disallow“ wird nicht zwischen Groß- und Kleinschreibung unterschieden, sodass es dir überlassen ist, ob du sie großschreiben willst oder nicht.
Die Werte innerhalb jeder Anweisung unterscheiden jedoch nach Groß- und Kleinschreibung.
Zum Beispiel ist /Foto/ nicht dasselbe Verzeichnis wie /foto/.
In der Praxis werden die Anweisungen „Allow“ und „Disallow“ oft großgeschrieben, da dies die Datei für Menschen leichter lesbar macht.
Die Anweisung „Allow“
Die Anweisung „Allow“ erlaubt Suchmaschinen, ein Unterverzeichnis oder eine bestimmte Seite zu crawlen, auch wenn es/sie sich in einem sonst gesperrten Verzeichnis befindet.
Wenn du beispielsweise alle deine Blogartikel außer einem vom Crawlen ausschließen willst, könnte deine Anweisung wie folgt aussehen:
User-agent: Googlebot
Disallow: /blog
Allow: /blog/beispiel-artikelHinweis: Nicht alle Suchmaschinen erkennen diese Anweisung an, aber Google und Bing unterstützen sie.
Die Anweisung „Sitemap“
Die Anweisung „Sitemap“ teilt Suchmaschinen mit, wo sie deine XML-Sitemap finden können, insbesondere Bing, Yandex und Google.
Sitemaps enthalten meist ein Verzeichnis der Seiten, die von Suchmaschinen gecrawlt und indexiert werden sollen.
Du findest diese Anweisung ganz oben oder unten in einer robots.txt-Datei. Und so sieht sie aus:
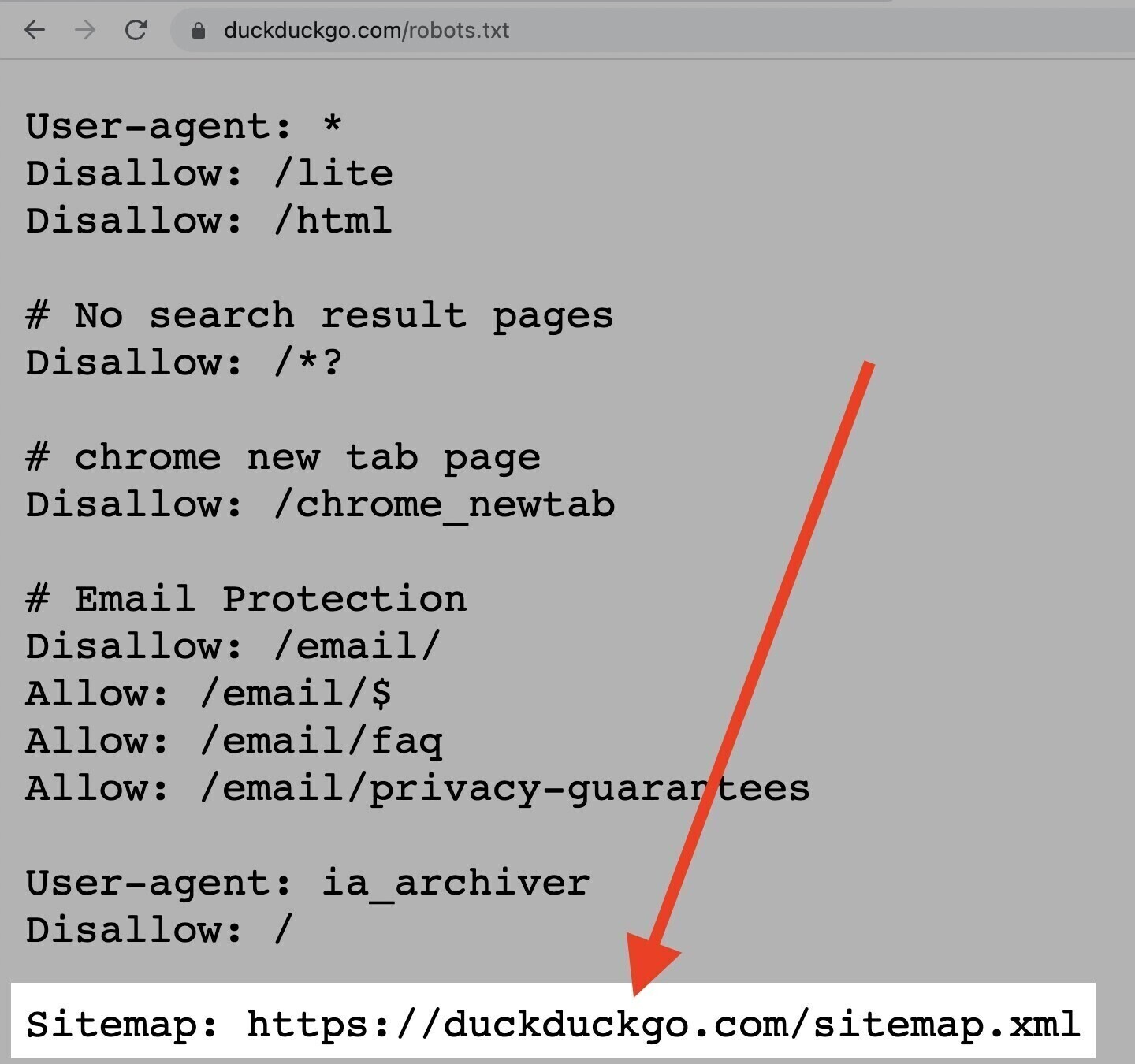
Abgesehen davon kannst (und solltest) du deine XML-Sitemap auch über deren Webmaster-Tools bei jeder Suchmaschine einreichen.
Suchmaschinen werden deine Website wahrscheinlich früher oder später von selbst crawlen, aber durch das Einreichen einer Sitemap geht es schneller.
Wenn du dies nicht möchtest, ist das Hinzufügen einer „Sitemap“-Anweisung zu deiner robots.txt-Datei eine gute, schnelle Alternative.
Die Anweisung „Crawl-Delay“
Die Anweisung „Crawl-Delay“ gibt eine Crawl-Verzögerung in Sekunden an. Dies soll verhindern, dass Crawler einen Server überfordern (und damit deine Website verlangsamen).
Google unterstützt diese Anweisung jedoch nicht mehr.
Wenn du eine Crawling-Rate für den Googlebot festlegen willst, musst du dies in der Search Console tun.
Bing und Yandex hingegen unterstützen die Crawl-Delay-Anweisung.
Und so benutzt du sie: Wenn du beispielsweise willst, dass ein Crawler nach jeder Crawl-Aktion 10 Sekunden wartet, kannst du die Verzögerung wie folgt auf 10 setzen:
User-agent: *
Crawl-delay: 10Die Anweisung „Noindex“
Die robots.txt-Datei teilt einem Bot mit, was er crawlen kann und was nicht. Aber sie kann einer Suchmaschine nicht mitteilen, welche URLs nicht indexiert oder in den Suchergebnissen angezeigt werden sollen.
Eine per robots.txt ausgeschlossene Seite wird weiterhin in den Suchergebnissen angezeigt, nur dass der Bot nicht weiß, was sich darauf befindet. das sieht dann etwa so aus:

SEO-Experten haben lange Zeit geglaubt, dass Google die Anweisung „Noindex“ befolgt, obwohl das offiziell nie der Fall war.
Am 1. September 2019 hat das Unternehmen dann unmissverständlich klargestellt, dass diese Anweisung von Google nicht unterstützt wird.
Wenn du eine Seite oder Datei zuverlässig von der Anzeige in den Suchergebnissen ausschließen willst, vermeide diese Anweisung und verwende stattdessen ein Meta-Robots-noindex-Tag.
So erstellst du eine robots.txt-Datei
Wenn du noch keine robots.txt-Datei hast, ist es nicht schwer, eine zu erstellen.
Du kannst dazu einen robots.txt-Generator verwenden oder es per Hand machen.
So erstellst du eine robots.txt-Datei in nur vier Schritten:
- Eine Textdatei erstellen und robots.txt nennen
- Der robots.txt-Datei Anweisungen hinzufügen
- Die robots.txt-Datei auf deine Website hochladen
- Deine robots.txt-Datei testen
1. Eine Datei erstellen und robots.txt nennen
Öffne zunächst ein .txt-Dokument mit einem beliebigen Texteditor oder Webbrowser.
Hinweis: Verwende kein Textverarbeitungsprogramm, da diese Dateien häufig in proprietären Formaten speichern, die zufällige Zeichen enthalten können.
Benenne als Nächstes das Dokument mit „robots.txt“. Mit anderen Namen funktioniert es nicht.
Jetzt kannst du mit der Eingabe deiner Anweisungen beginnen.
2. Der robots.txt-Datei Anweisungen hinzufügen
Eine robots.txt-Datei besteht aus einer oder mehreren Gruppen von Anweisungen, und jede Gruppe besteht aus mehreren Zeilen.
Jede Gruppe beginnt mit einem „User-Agent“ und enthält die folgenden Informationen:
- Für welchen User-Agent die Gruppe gilt
- Auf welche Verzeichnisse (Seiten) oder Dateien der User-Agent zugreifen kann
- Auf welche Verzeichnisse (Seiten) oder Dateien der User-Agent nicht zugreifen kann
- Eine Sitemap (optional), um Suchmaschinen mitzuteilen, welche Seiten und Dateien deiner Meinung nach wichtig sind
Crawler ignorieren Zeilen, die keiner dieser Anweisungen entsprechen.
Angenommen, du willst Google daran hindern, dein /kunden/-Verzeichnis zu crawlen, da es nur für den internen Gebrauch bestimmt ist.
Die erste Gruppe würde dann etwa so aussehen:
User-agent: Googlebot
Disallow: /kunden/Wenn du weitere Anweisungen wie diese für Google hast, kannst du sie in einer neuen Zeile direkt darunter einfügen, etwa so:
User-agent: Googlebot
Disallow: /kunden/
Disallow: /nicht-fuer-googleWenn du mit den spezifischen Anweisungen für Google fertig bist, drücke zweimal die Eingabetaste, um eine neue Gruppe von Anweisungen zu beginnen.
Widmen wir die nächste Gruppe allen Suchmaschinen und hindern diese daran, die Verzeichnisse /archiv/ und /support/ zu crawlen, da sie privat und nur für den internen Gebrauch bestimmt sind.
Das würde so aussehen:
User-agent: Googlebot
Disallow: /kunden/
Disallow: /nicht-fuer-google
User-agent: *
Disallow: /archiv/
Disallow: /support/Wenn du fertig bist, kannst du noch deine Sitemap hinzufügen.
Die vollständige robots.txt-Datei würde dann etwa so aussehen:
User-agent: Googlebot
Disallow: /kunden/
Disallow: /nicht-fuer-google
User-agent: *
Disallow: /archiv/
Disallow: /support/
Sitemap: https://www.deinewebsite.de/sitemap.xmlSpeichere nun die Datei ab. Wie gesagt: unbedingt unter dem Namen „robots.txt“!
Hinweis: Crawler lesen von oben nach unten und folgen der ersten spezifischsten Gruppe von Regeln. Beginne also mit bestimmten User-Agents und platziere die Anweisungen mit dem allgemeinen Platzhalter (*) darunter, die für alle Crawler gelten.
3. Die robots.txt-Datei auf deine Website hochladen
Nachdem du deine robots.txt-Datei auf deinem Computer gespeichert hast, lade sie auf deine Website hoch, sodass sie für Suchmaschinen zum Crawlen verfügbar ist.
Leider gibt es kein universelles Tool, das bei diesem Schritt helfen kann.
Die richtigen Schritte zum Hochladen der robots.txt-Datei hängen von der Dateistruktur und dem Webhosting deiner Website ab.
Informiere dich am besten online oder wende dich an deinen Hosting-Provider, um Hilfe beim Hochladen deiner robots.txt-Datei zu erhalten.
Du kannst beispielsweise nach „robots.txt-Datei in WordPress hochladen“ suchen, um spezifische Anweisungen zu finden.
Hier sind einige Artikel, die erklären, wie du deine robots.txt-Datei auf den beliebtesten Plattformen hochladen kannst:
- Robots.txt-Datei in WordPress
- Robots.txt-Datei in Wix
- Robots.txt-Datei in Joomla
- Robots.txt-Datei in Shopify
- Robots.txt-Datei in BigCommerce
Nach dem Upload deiner robots.txt-Datei solltest du noch überprüfen, ob sie korrekt abrufbar ist und Google sie lesen kann.
4. Deine robots.txt-Datei testen
Teste zunächst, ob deine robots.txt-Datei korrekt hochgeladen wurde und öffentlich zugänglich ist.
Öffne ein privates Fenster in deinem Browser und suche nach deiner robots.txt-Datei, indem du die URL eingibst.
Zum Beispiel: https://semrush.com/robots.txt.
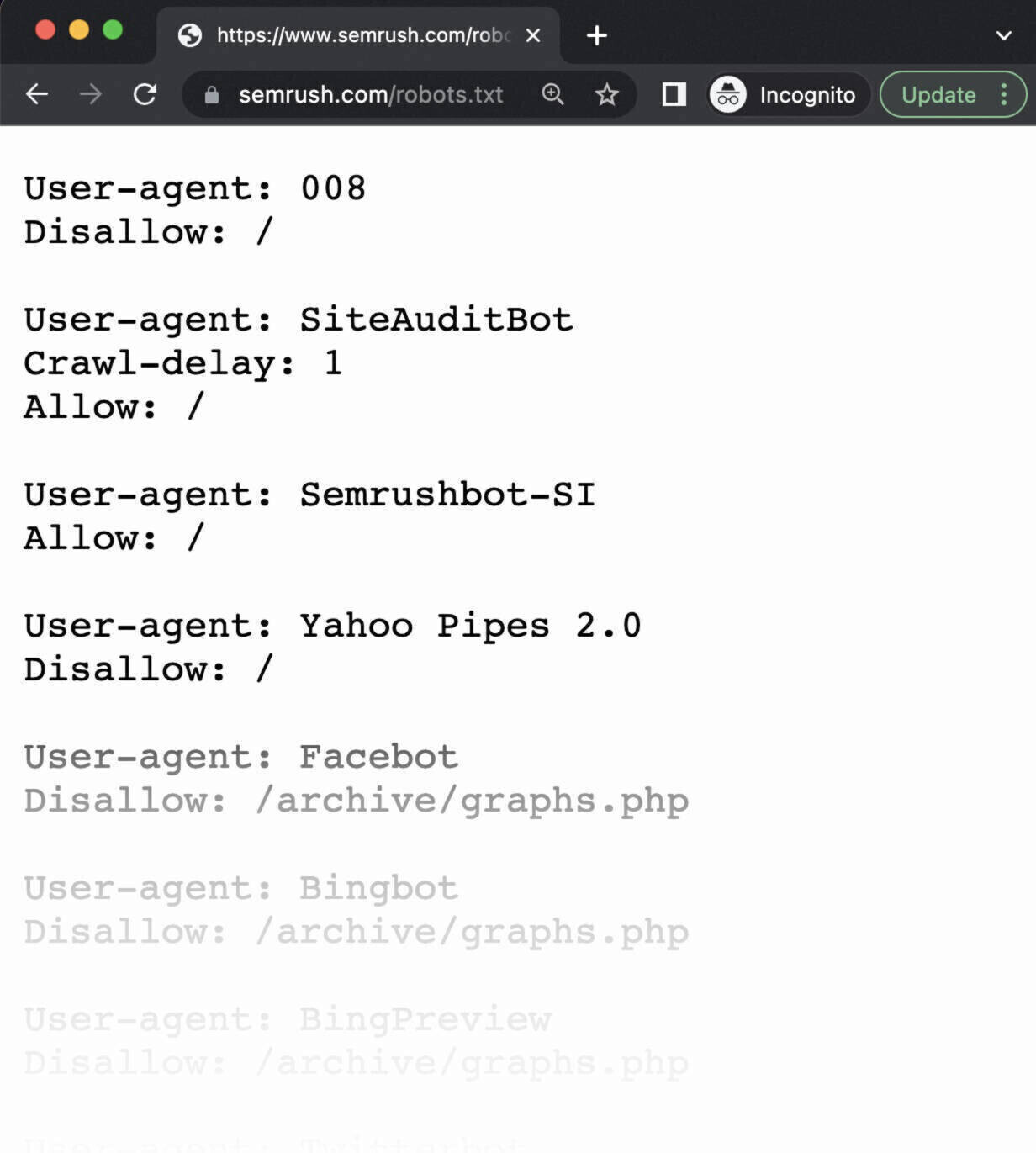
Wenn du deine robots.txt-Datei mit den richtigen Anweisungen siehst, kannst du als Nächstes das Markup (den HTML-Code) testen.
Google bietet zwei Optionen zum Testen des robots.txt-Markups:
- Den robots.txt-Tester in der Search Console
- Googles Open-Source-Bibliothek für robots.txt (für Fortgeschrittene)
Da die zweite Option eher auf fortgeschrittene Entwickler ausgerichtet ist, wirst du deine robots.txt-Datei wahrscheinlich eher in der Search Console testen wollen.
Hinweis: Du musst ein Search Console-Konto eingerichtet haben, um deine robots.txt-Datei zu testen.
Gehe zum robots.txt-Tester und klicke auf „robots.txt-Tester öffnen“.
Wenn du deine Website noch nicht mit deinem Search-Console-Konto verknüpft hast, musst du zuerst eine Property hinzufügen.

Dann musst du bestätigen, dass du der wirkliche Eigentümer der Website bist.

Wenn du bereits über eine bestätigte Property verfügst, wähle diese aus der Dropdown-Liste auf der Homepage des Testers aus.

Der Tester identifiziert alle Syntaxwarnungen oder Logikfehler und weist dich darauf hin.
Er zeigt dir auch die Anzahl der Warnungen und Fehler direkt unter dem Editor.
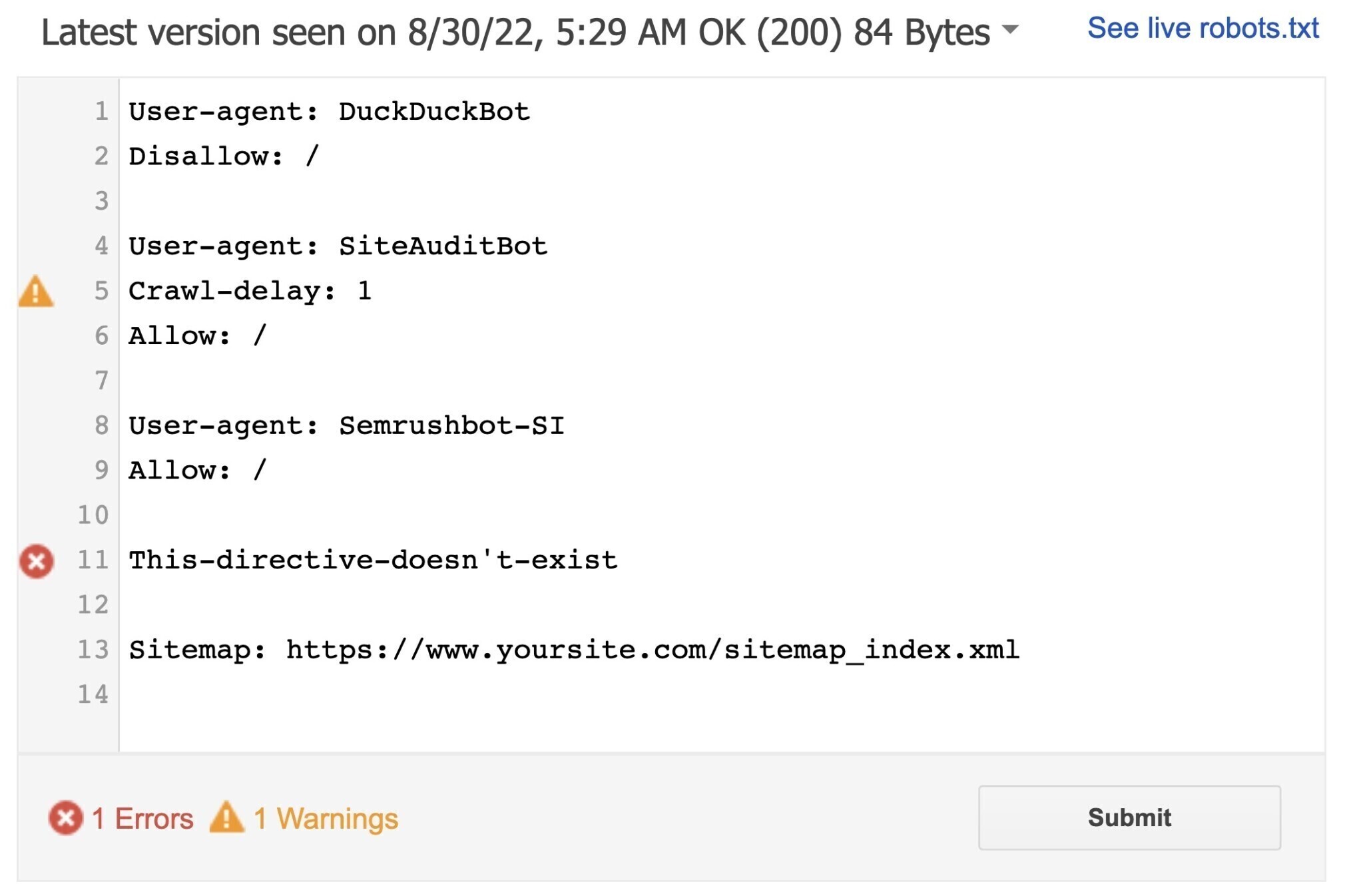
Du kannst Fehler oder Warnungen direkt auf der Seite bearbeiten und den Test beliebig oft wiederholen.
Beachte dabei, dass auf der Seite vorgenommene Änderungen nicht auf deiner Website gespeichert werden. Das Tool nimmt keine Änderungen an der eigentlichen Datei auf deiner Website vor. Es testet nur die im Tool gehostete Kopie, damit du eventuelle Fehler identifizieren kannst.
Um Änderungen zu implementieren, kopiere die korrigierten Anweisungen und füge sie in die robots.txt-Datei auf deiner Website ein.
Profi-Tipp: Richte monatliche technische SEO-Audits mit dem Site Audit von Semrush ein, um nach neuen Problemen mit deiner robots.txt-Datei zu suchen. Es ist wichtig, die Datei im Auge zu behalten, da selbst geringfügige Änderungen die Indexierbarkeit deiner Website beeinträchtigen können.
Hier findest du das Site Audit von Semrush.
Best Practices für robots.txt
Behalte diese Best Practices im Hinterkopf, wenn du deine robots.txt-Datei erstellst, um häufige Fehler zu vermeiden.
Schreibe jede Anweisung in eine neue Zeile
Jede Anweisung sollte in einer neuen Zeile stehen.
Andernfalls können Suchmaschinen sie nicht lesen und deine Anweisungen werden ignoriert.
Falsch:
User-agent: * Disallow: /admin/
Disallow: /verzeichnis/Richtig:
User-agent: *
Disallow: /admin/
Disallow: /verzeichnis/Verwende jeden User-Agent nur einmal
Bots haben nichts dagegen, wenn du denselben User-Agent mehrmals angibst.
Wenn du aber jeden nur einmal ansprichst, bleibt es übersichtlich und die Fehlerwahrscheinlichkeit ist kleiner.
Falsch:
User-agent: Googlebot
Disallow: /beispiel-seite
User-agent: Googlebot
Disallow: /beispiel-seite-2In diesem Beispiel wird der User-Agent Googlebot zweimal aufgeführt, was nicht optimal ist.
Richtig:
User-agent: Googlebot
Disallow: /beispiel-seite
Disallow: /beispiel-seite-2Im ersten Beispiel würde Google immer noch den Anweisungen folgen und keine Seite crawlen.
Alle Anweisungen für einen User-Agent zusammenzufassen ist aber sauberer und hilft dir, den Überblick zu behalten.
Nutze Platzhalter, um klare Anweisungen zu formulieren
Du kannst Platzhalter (*) nutzen, um eine Anweisung auf alle User-Agents anzuwenden und URL-Muster zu erfassen.
Wenn du beispielsweise verhindern willst, dass Suchmaschinen auf URLs mit Parametern zugreifen, könntest du diese URLs theoretisch alle nacheinander auflisten.
Falsch:
User-agent: *
Disallow: /schuhe/vans?
Disallow: /schuhe/nike?
Disallow: /schuhe/adidas?Aber das ist ineffizient. Besser ist es, deine Anweisungen mit einem Platzhalter zu vereinfachen.
Richtig:
User-agent: *
Disallow: /schuhe/*?Das Beispiel verwendet das Sternchen als Platzhalter, um alle Suchmaschinen-Bots daran zu hindern, sämtliche URLs mit Fragezeichen (für Parameter) unter dem /schuhe/-Verzeichnis zu crawlen.
Verwende „$“, um das Ende einer URL anzuzeigen
Das „$“ kennzeichnet das Ende einer URL.
Wenn du beispielsweise das Crawlen aller .jpg-Dateien auf deiner Website verhindern willst, könntest du diese Dateien einzeln auflisten.
Aber das wäre ineffizient.
Falsch:
User-agent: *
Disallow: /foto-a.jpg
Disallow: /foto-b.jpg
Disallow: /foto-c.jpgViel schöner ist es, die „$“-Funktion zu verwenden:
Richtig:
User-agent: *
Disallow: /*.jpg$In diesem Beispiel kann /hund.jpgnicht gecrawlt werden, /hund.jpg?p=32414 dagegen schon, weil es nicht auf .jpg endet.
Der „$“-Ausdruck ist unter bestimmten Umständen wie oben eine hilfreiche Funktion, kann aber auch gefährlich sein.
Du kannst damit leicht unbeabsichtigt Inhalte freigeben. Sei bei der Verwendung also vorsichtig.
Nutze die Raute (#), um Kommentare hinzuzufügen
Crawler ignorieren jede Zeile, die mit einer Raute (#) beginnt.
Daher verwenden Entwickler häufig Rauten, um Kommentare in eine robots.txt-Datei einzufügen. Kommentare helfen, die Datei organisiert und leicht lesbar zu halten.
Kommentare in einer robots.txt-Datei sehen etwa so aus:
User-agent: *
#Landing-Pages
Disallow: /landing/
Disallow: /lp/
#Dateien
Disallow: /dateien/
Disallow: /private-dateien/
#Websites
Allow: /website/*
Disallow: /website/suche/*Entwickler fügen gelegentlich auch lustige Botschaften in robots.txt-Dateien ein, weil sie wissen, dass Benutzer sie selten sehen.
In der robots.txt-Datei von YouTube heißt es beispielsweise:
„Entstanden in ferner Zukunft (im Jahr 2000) nach dem Roboteraufstand Mitte der 90er, der alle Menschen auslöschte.“

Und die robots.txt von Nike enthält die Worte „Just crawl it“ – eine augenzwinkernde Anspielung auf den Slogan „Just do it“ – sowie das Logo der Marke:

Verwende separate robots.txt-Dateien für verschiedene Subdomains
Robots.txt-Dateien steuern nur das Crawling-Verhalten auf der Subdomain, auf der sie gehostet sind.
Wenn du also das Crawling auf einer anderen Subdomain steuern möchtest, brauchst du eine separate robots.txt-Datei.
Wenn deine Hauptwebsite auf domain.de und dein Blog auf der Subdomain blog.domain.de zu finden ist, sind zwei robots.txt-Dateien nötig.
Eine für das Root-Verzeichnis der Hauptdomain und die andere für das Root-Verzeichnis des Blogs.
Mehr erfahren
Nachdem du nun genau weißt, wie robots.txt-Dateien funktionieren, findest du hier einige weitere Artikel, um deine Kenntnisse zu vertiefen: