Wie Semrush Traffic-Daten in Traffic-Informationen verwandelt
Vielleicht haben Sie sich schon einmal gefragt, woher die Daten stammen, die Sie in unseren Tools Traffic Analytics und Market Explorer sehen.
Dieser Artikel legt die wichtigsten Prozesse offen – von der Erfassung von Rohdaten bis zu gebrauchsfertigen Einblicken innerhalb der Tools.
Im Wesentlichen durchlaufen alle Daten vier Hauptphasen:
- Datensammlung
- Datenbereinigung
- Datenmodellierung
- Datenbereitstellung
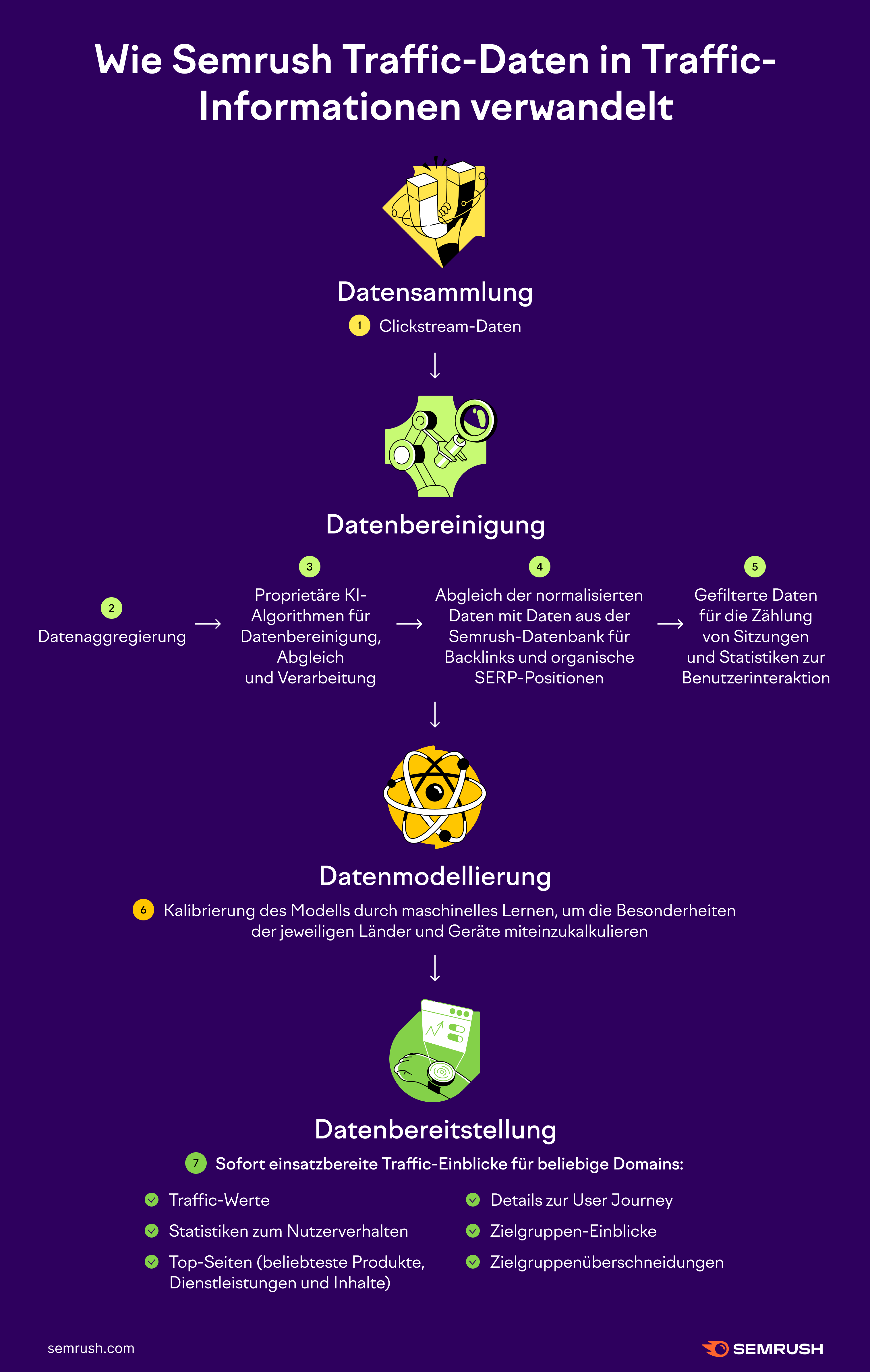
Datensammlung
Wir erhalten alle ein bis zwei Tage terabyteweise Daten aus einem Pool verschiedener Drittanbieter. Diese Daten nennt man Clickstream-Daten – sie bieten eine aggregierte Ansicht der User Journeys von Millionen von echten, aber anonymisierten Internetnutzern und verfolgen deren Online-Aktivitäten.
Anhand von Clickstream-Daten können wir allgemeine Statistiken und Trends zum Nutzerverhalten ermitteln.
Datenbereinigung
Alle Daten werden aggregiert und an ein gemeinsames Format im System zur Traffic-Analyse angeglichen.
Mit unserem proprietären Modell zum maschinellen Lernen befreien wir die Daten von verschiedenen Anomalien.
Während ihres Lernprozesses beginnt unsere KI, Muster zu erkennen, ähnlich wie ein menschliches Gehirn, und verwandelt unser Modell in einen umfassenden Algorithmus, der Anomalien entdecken und fragwürdige Daten besser von aussagekräftigen Daten trennen kann.
Außerdem gleichen wir die Daten mit der Backlink-Datenbank von Semrush und der Datenbank für organische SERP-Positionen ab. So können wir sehen, ob sie zu den Besonderheiten der einzelnen Länder und Geräte passen.
Sobald unser Algorithmus die Daten überprüft hat, erhalten wir ein realistischeres Bild von den Sitzungen der generischen Nutzer. Auf diesem Datensatz bauen wir unsere Interaktions-Metriken auf.
Datenmodellierung und -bereitstellung
In dieser Phase haben wir eine Big Data-Box, in der wir den Clickstream- und die proprietären Daten speichern.
Bevor wir diese Daten in unser Modell für maschinelles Lernen einfließen lassen, werden sie noch einmal überprüft. Wir normalisieren die Daten und berücksichtigen dabei die Popularität der Domain sowie das „typische“ Nutzerverhalten für verschiedene Länder, Demografien, Geräte und Branchen.
Ein Nutzer aus den USA, der das Internet nur einmal im Monat verwendet, wird zum Beispiel eher Google (eine beliebte Domain) als die Website der FDA (eine etwas weniger besuchte Domain) besuchen. Daher lassen wir den Teil der Nutzer mit sehr schwachen Aktivitätsmustern außen vor, um genauere Daten sowohl für beliebtere als auch für weniger stark besuchte Websites zu erhalten.
So können wir aussagekräftigere Daten in unser Modell für maschinelles Lernen einfließen lassen.
Der Algorithmus durchläuft ein überwachtes Lernen, was bedeutet, dass unsere Big-Data-Technologie sich jeden Tag weiter verbessert und dazu lernt.
Tägliche und wöchentliche Traffic-Daten
Seit September 2023 stellt Semrush jetzt tägliche und wöchentliche Daten im Tool Traffic Analytics bereit. Diese verbesserte Funktion geht mit der Einführung eines neuen KI-Modells einher, das eine höhere Granularität, Genauigkeit und Stabilität des Traffics bietet.
Während wir bisher nur monatliche Daten verarbeitet haben, ist mit dem neuen Modell die Verarbeitung von täglichen Daten möglich. Die Verarbeitung täglicher Daten ermöglicht uns, tägliche und wöchentliche Traffic-Metriken für die Domains von Mitbewerbern bereitzustellen.
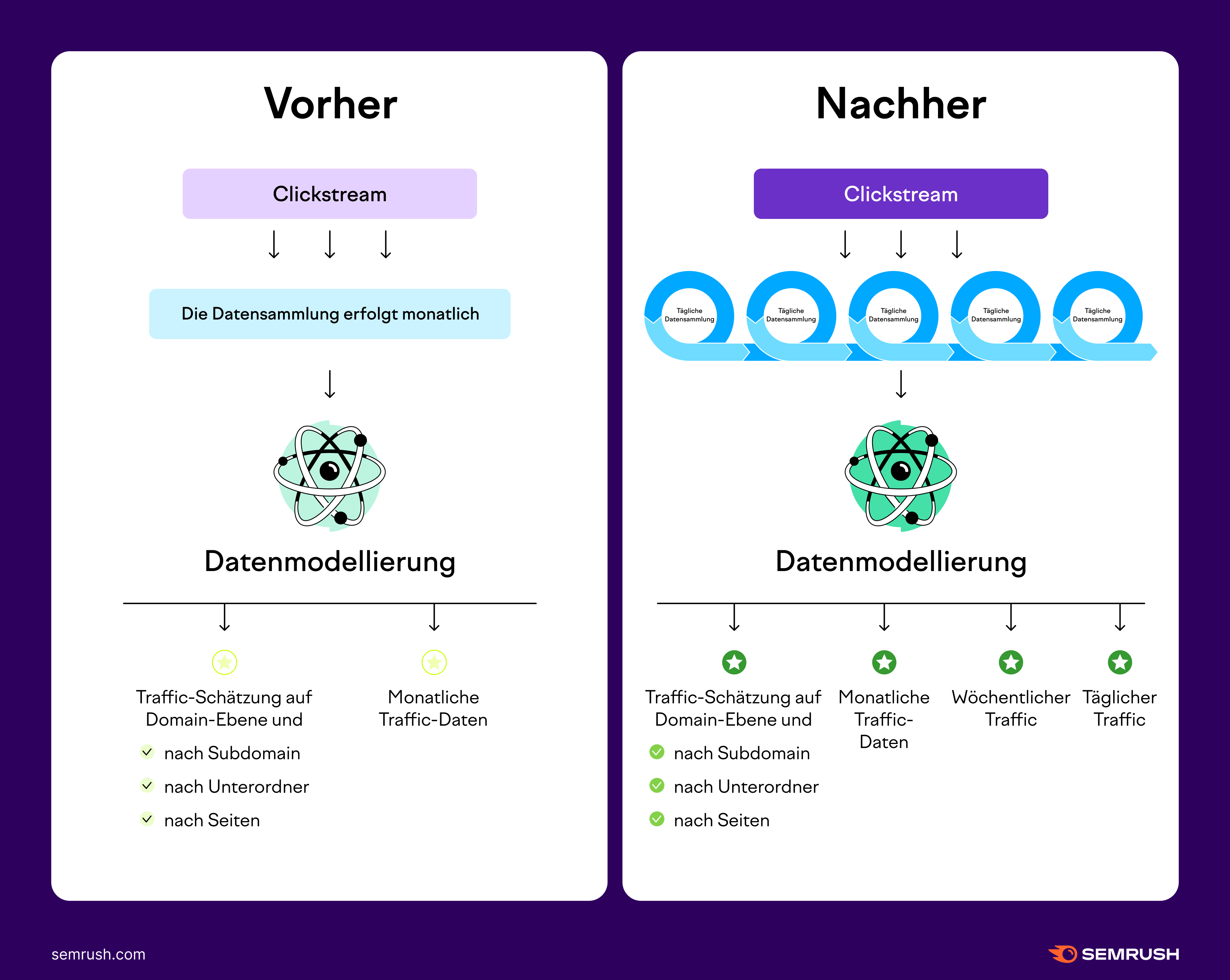
Dieses Update kann sich auf alle Statistiken in den Berichten von Semrush Traffic Analytics auswirken, einschließlich Verlaufsdaten bis zurück ins Jahr 2017. Mit diesem verbesserten KI-Modell, das zuverlässigere Daten liefert, können wir unsere früheren Schätzungen schärfer fokussieren, was zu einigen Verschiebungen bei den Metriken führen kann.
Zur Abdeckung der Traffic-Daten durch Semrush
Bei der Datenqualität gibt es keine Grenze nach oben. Daher arbeiten wir ständig daran, unsere Tools um neue Daten zu erweitern. Unsere KI- und Big-Data-Technologien lernen währenddessen immer weiter und entwickeln ihre Algorithmen weiter.
Wir haben kürzlich unser Datenverarbeitungsmodell für die Erfassung von Traffic-Daten aktualisiert, wodurch wir unsere Abdeckung der Traffic-Daten um 20 % erweitern konnten.
Unten können Sie sich anschauen, was sich genau geändert hat.

*Events stellen die Tatsache dar, dass ein Nutzer eine bestimmte Internetseite besucht hat.
**Sitzungen sind eine Reihe von Aktionen, die ein Nutzer innerhalb eines bestimmten Zeitraums auf einer bestimmten Website ausführt. In Semrush .Trends bezeichnen wir Sitzungen als Besuche.
Häufig gestellte Fragen
- Wie Semrush Traffic-Daten in Traffic-Informationen verwandelt
Workflows
- How to Monitor Market Trends
- How to Evaluate a Prospective Partner with Semrush
- How to Quickly Overview a Niche
- How to Estimate a New Country’s Market Potential for Your Business
- How to Evaluate New Markets with Semrush .Trends
- How to Segment a Target Audience
- How to Analyze Competitor Content Strategies and Optimize Your Own
- How to Find Partners to Improve your Marketing Strategy
- How to Design and Deliver an Offer for Your Target Audience