Weshalb werden nur wenige Seiten meiner Website gecrawlt?
Wenn Sie festgestellt haben, dass nur 4-6 Seiten Ihrer Website gecrawlt werden (Ihre Homepage, die URLs der Sitemaps und die robots.txt), liegt das wahrscheinlich daran, dass unser Bot keine ausgehenden internen Links auf Ihrer Homepage finden konnte. Im Folgenden finden Sie mögliche Gründe für dieses Problem.
Möglicherweise gibt es auf Ihrer Hauptseite keine ausgehenden internen Links, oder sie sind in JavaScript eingebettet. Unser Bot analysiert JavaScript-Inhalte nur in den Paketstufen Guru und Business des Abonnements für das SEO Toolkit. Daher werden wir, sofern Sie nicht über die Paketstufe Guru oder Business verfügen und Ihre Startseite Links zu anderen Teilen Ihrer Website innerhalb von JavaScript-Elementen enthält, diese Seiten nicht erkennen oder crawlen.
Auch wenn das Crawlen von JavaScript nur in den Paketstufen Guru und Business verfügbar ist, können wir dennoch den HTML-Inhalt von Seiten crawlen, die JavaScript-Elemente enthalten. Darüber hinaus können unsere Performance-Prüfungen die Parameter Ihrer JavaScript- und CSS-Dateien überprüfen – unabhängig von Ihrer Paketstufe.
In beiden Fällen gibt es einen Weg, um sicherzustellen, dass unser Bot Ihre Seiten crawlen kann. Dafür müssen Sie in Ihren Kampagnen-Einstellungen „Zu crawlende Seiten“ von „Website“ auf „Sitemap“ oder „URLs aus Datei“ ändern:
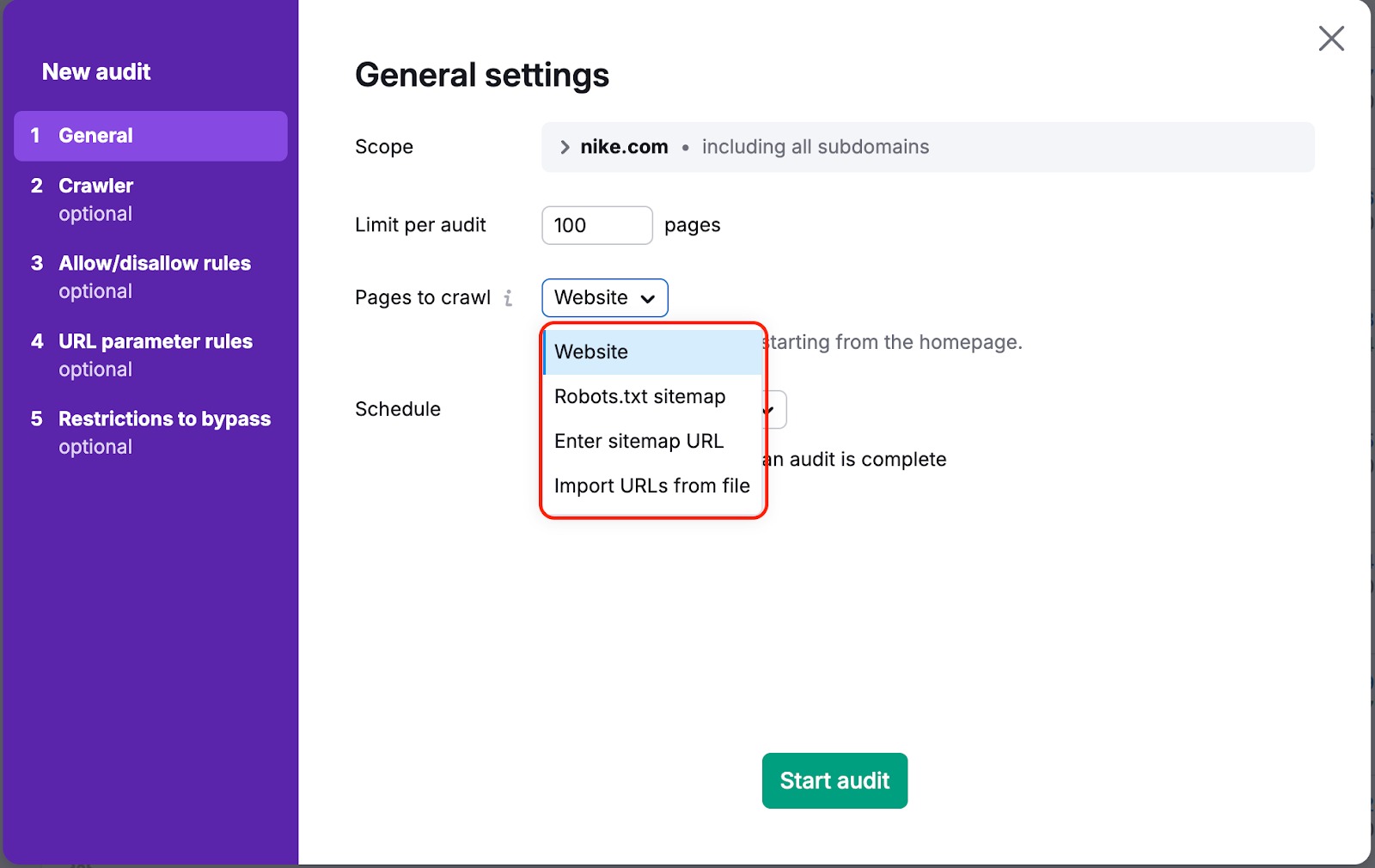
„Website" ist eine Standardquelle. Das bedeutet, dass wir Ihre Website mit einem Breitensuch-Algorithmus crawlen und durch die Links navigieren, die wir im Code Ihrer Seite sehen - beginnend mit der Startseite.
Wenn Sie eine der anderen Optionen wählen, crawlen wir die Links, die sich in der Sitemap oder in der von Ihnen hochgeladenen Datei befinden.
Unser Crawler könnte auf einigen Seiten in der robots.txt der Website oder durch noindex/nofollow-Tags blockiert worden sein. Ob dies der Fall ist, kannst du in deinem Bericht über gecrawlte Seiten überprüfen:
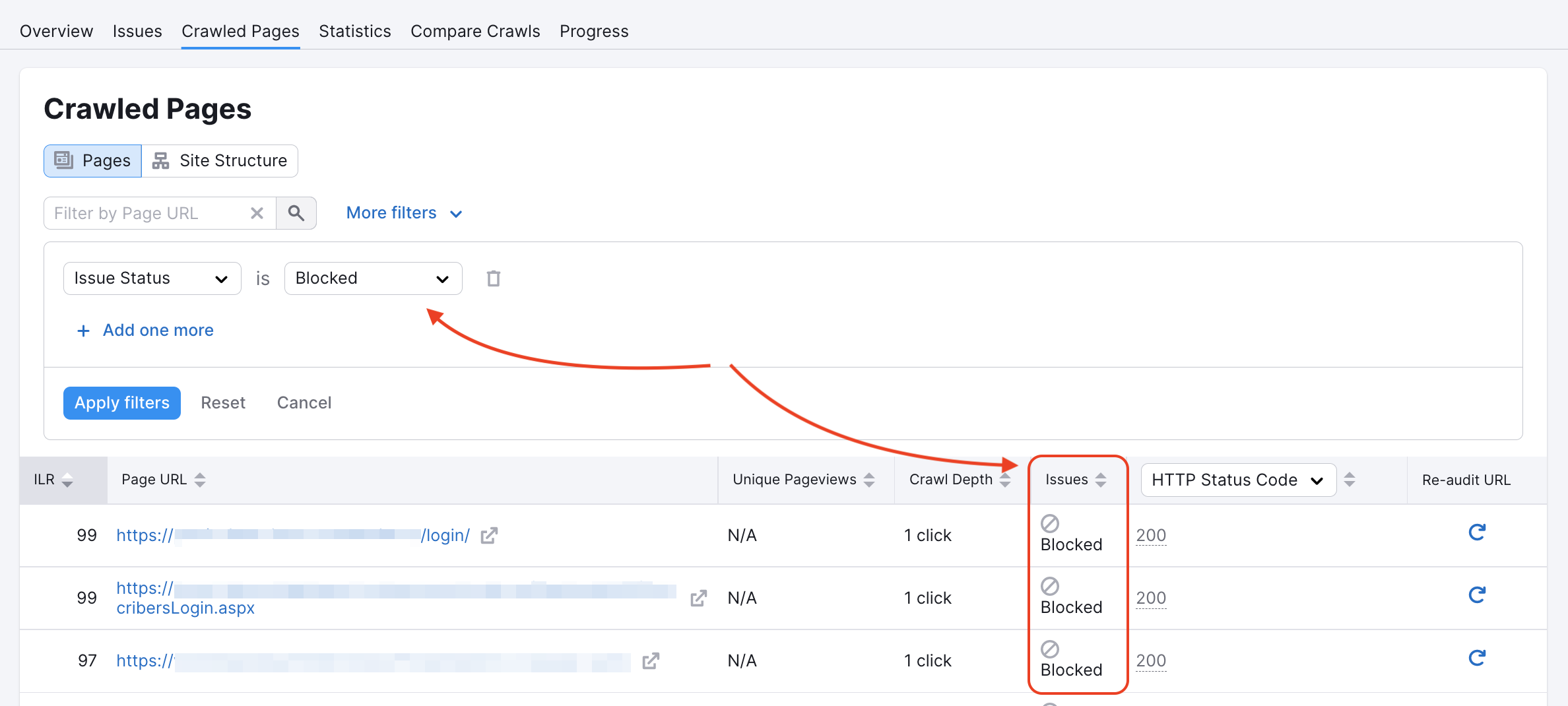
Sie können Ihre Robots.txt auf Disallow-Befehle überprüfen, die es Crawlern wie unseren unmöglich machen würden, auf Ihre Website zuzugreifen.
Wenn Sie den untenstehenden Code auf der Hauptseite einer Website sehen, bedeutet dies, dass wir die Links nicht indexieren bzw. ihnen nicht folgen dürfen und dass unser Zugriff blockiert ist. Oder eine Seite, die mindestens eine der folgenden beiden Angaben enthält: „nofollow", „none", verursacht einen Crawling-Fehler.
Weitere Informationen zu diesen Fehlern finden Sie in unserem Artikel zur Fehlerbehebung.
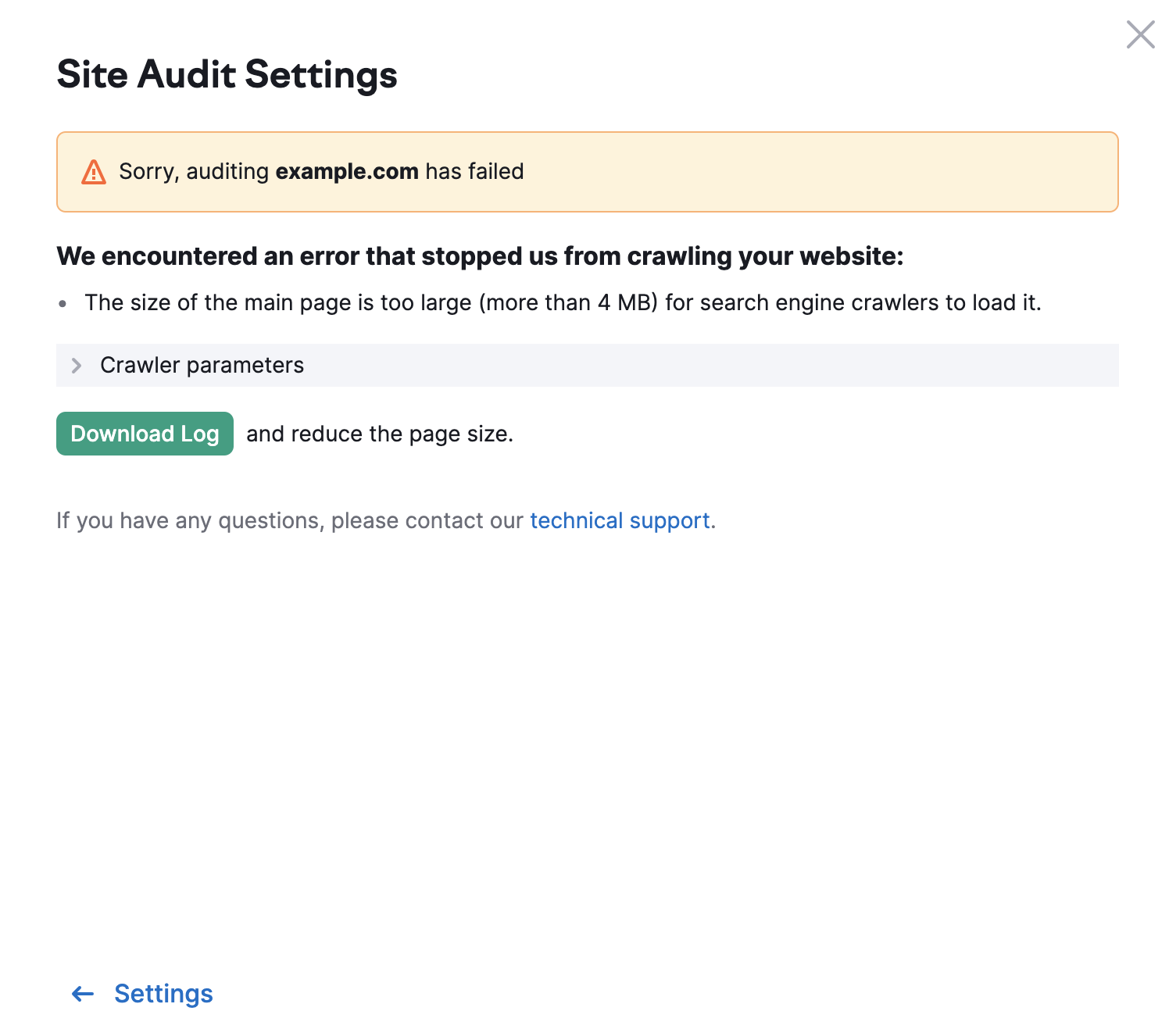
Die Grenze für andere Seiten deiner Website liegt bei 2 MB. Wenn eine Seite eine zu große HTML-Größe hat, wird die folgende Fehlermeldung angezeigt:
