Wenn Sie Ihren ersten Ordner in Semrush erstellen, wird Site Audit automatisch für die angegebene Domain konfiguriert und gestartet. Sie können die Ergebnisse anzeigen, indem Sie im linken Menü das Site Audit Tool aufrufen oder zur Startseite navigieren, nachdem der erste Crawl abgeschlossen ist.
Für alle nachfolgenden Ordner, die Sie erstellen, müssen Sie Site Audit manuell konfigurieren. Erstellen Sie dazu einen neuen Ordner in Site Audit und befolgen Sie die Anweisungen, um Ihre Audit-Kampagne zu konfigurieren und zu starten.
Falls Sie Probleme haben, Ihr Site Audit auszuführen, schauen Sie sich bitte Fehlerbehebung bei Site Audit an, um Unterstützung zu erhalten.
Allgemeine Einstellungen
Sie werden zum ersten Teil des Einrichtungsassistenten geleitet: „Allgemeine Einstellungen“. Hier aus können Sie entweder „Audit starten“ auswählen, das sofort ein Audit Ihrer Website mit unseren Standard-Einstellungen durchführt. Oder Sie passen die Einstellungen für Ihr Audit nach Ihren Wünschen an. Aber keine Sorge: Sie können Ihre Einstellungen jederzeit ändern und Ihr Audit erneut ausführen, um einen genauer eingegrenzten Bereich Ihrer Website zu crawlen, nachdem Sie die initiale Einrichtung abgeschlossen haben.
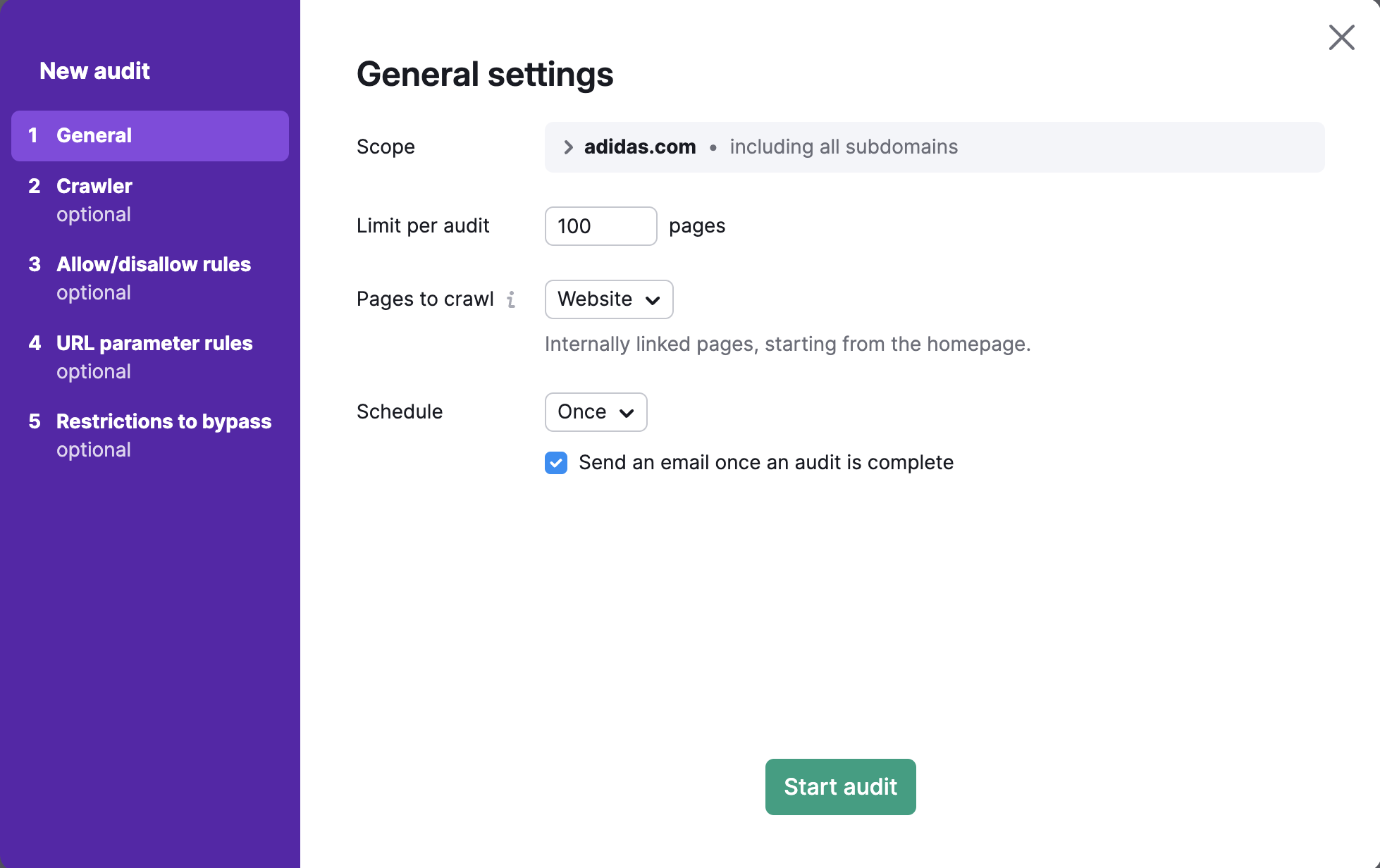
Crawl-Bereich
Um eine bestimmte Domain, Subdomain oder einen Unterordner zu crawlen, können Sie dies im Feld „Umfang“ eingeben. Wenn Sie eine Domain in dieses Feld eingeben, können Sie über ein Kontrollkästchen auswählen, dass alle Subdomains Ihrer Domain gecrawlt werden sollen.
Standardmäßig überprüft das Tool die Root-Domain. Dabei sind alle verfügbaren Subdomains und Unterordner Ihrer Website eingeschlossen. In den Einstellungen von Site Audit können Sie Ihre Subdomain oder Ihren Unterordner als Crawl-Bereich angeben und das Häkchen bei „Alle Subdomains crawlen“ entfernen, falls Sie nicht möchten, dass andere Subdomains gecrawlt werden.
Nehmen wir an, Sie möchten nur den Blog Ihrer Website überprüfen. Sie können als Crawl-Bereich blog.semrush.com oder semrush.com/blog/angeben – je nachdem, ob es sich um eine Subdomain oder einen Unterordner handelt.
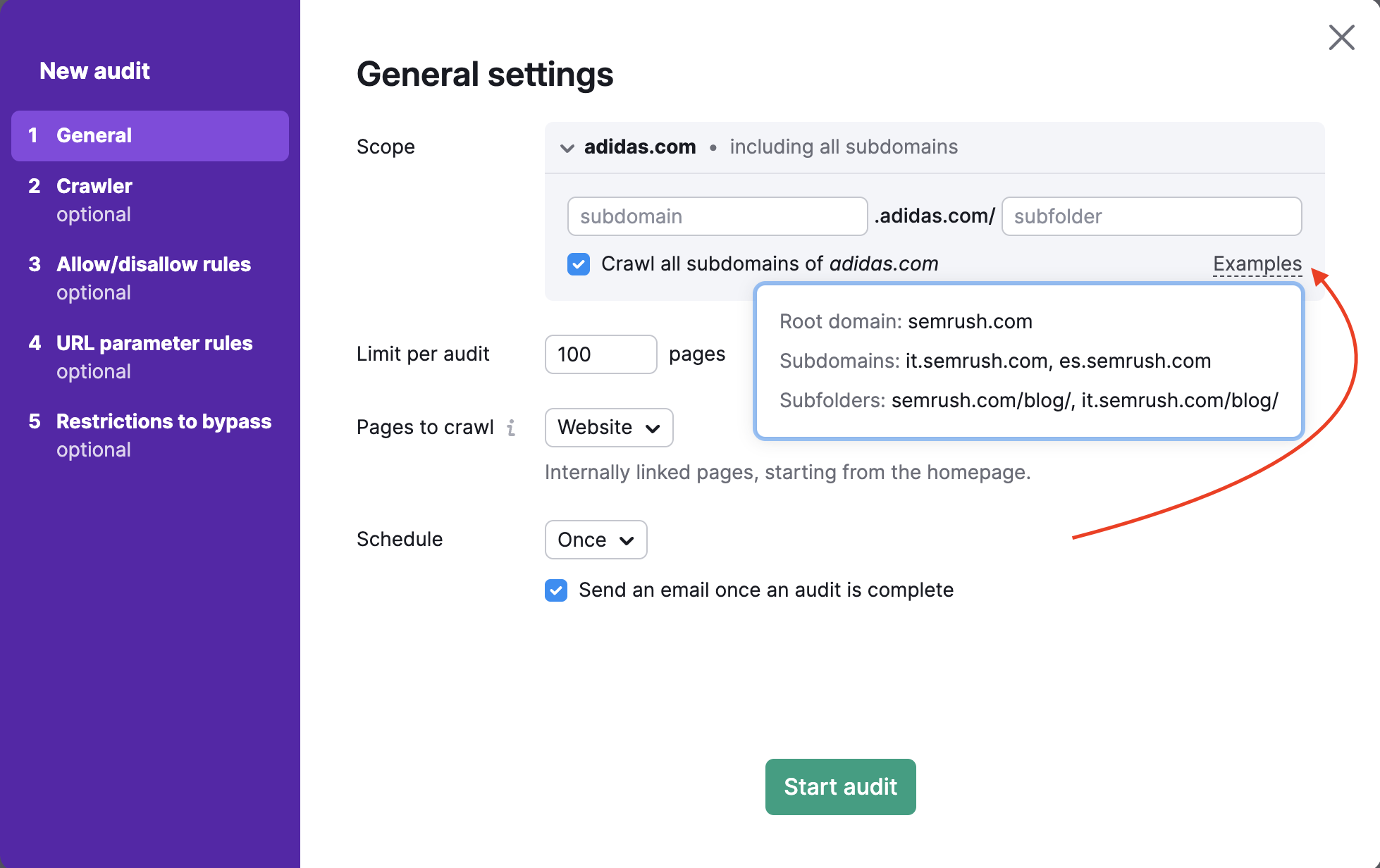
Limit der Seiten pro Audit
Als Nächstes wählen Sie aus, wie viele Seiten Sie pro Audit crawlen möchten. Sie sollten diese Zahl mit Bedacht wählen. Denn sie hängt von der Stufe Ihres Pakets ab und davon, wie oft Sie Ihre Website erneut prüfen möchten.
- Benutzer des SEO Toolkit Pro können bis zu 100.000 Seiten pro Monat und20.000 Seiten pro Audit crawlen
- Benutzer des SEO Toolkit Guru können bis zu 300.000 Seiten pro Monat und20.000 Seiten pro Audit crawlen
- Benutzer von Business SEO Toolkit können bis zu 1 Million Seiten pro Monat und 100.000 Seiten pro Audit crawlen
Zu crawlende Seiten
Die Einstellung von "Zu crawlende Seiten" bestimmt, wie der Site Audit-Bot von Semrush Ihre Website crawlt und die zu prüfenden Seiten findet. Zusätzlich zur Festlegung der Crawl-Quelle können Sie in den Schritten 3 und 4 des Einrichtungsassistenten Masken und Parameter zum Einschließen/Ausschließen beim konfigurieren.
Es gibt 4 Optionen, die Sie für „Zu crawlende Seiten“ festlegen können: Website, Sitemap in Robots.txt, Sitemap-URL eingeben und URLs aus Datei importieren.
1. Crawlen anhand der Website bedeutet, dass wir Ihre Website wie der GoogleBot crawlen, indem wir einen Breadth-first-Suchalgorithmus verwenden und durch die Links navigieren, die wir im Code Ihrer Seite finden – beginnend mit der Startseite.
Wenn Sie nur die wichtigsten Seiten einer Website crawlen möchten, können Sie statt der Website die Sitemap auswählen. So können beim Audit die wichtigsten Seiten gecrawlt werden und nicht nur diejenigen, die von der Startseite aus am leichtesten erreichbar sind.
2. Crawlen anhand der Sitemap in der Robots.txt bedeutet, dass wir nur die URLs crawlen, die in der Sitemap innerhalb der Robots.txt-Datei verlinkt sind.
3. Crawlen anhand der Sitemap-URL ist ähnlich wie das Crawlen anhand der „Sitemap in Robots.txt“, aber mit dieser Option können Sie Ihre konkrete Sitemap-URL eingeben.
Da Suchmaschinen Sitemaps verwenden, um zu erkennen, welche Seiten sie crawlen sollen, sollten Sie immer versuchen, Ihre Sitemap so aktuell wie möglich zu halten und sie in unserem Tool als Crawl-Quelle verwenden, um ein möglichst präzises Audit durchführen zu können.
Hinweis: Site Audit kann immer nur eine Sitemap-URL als Crawl-Quelle gleichzeitig verwenden. Falls Ihre Website mehrere Sitemaps hat, könnte die nächste Option (URLs aus Datei importieren) als Workaround funktionieren.
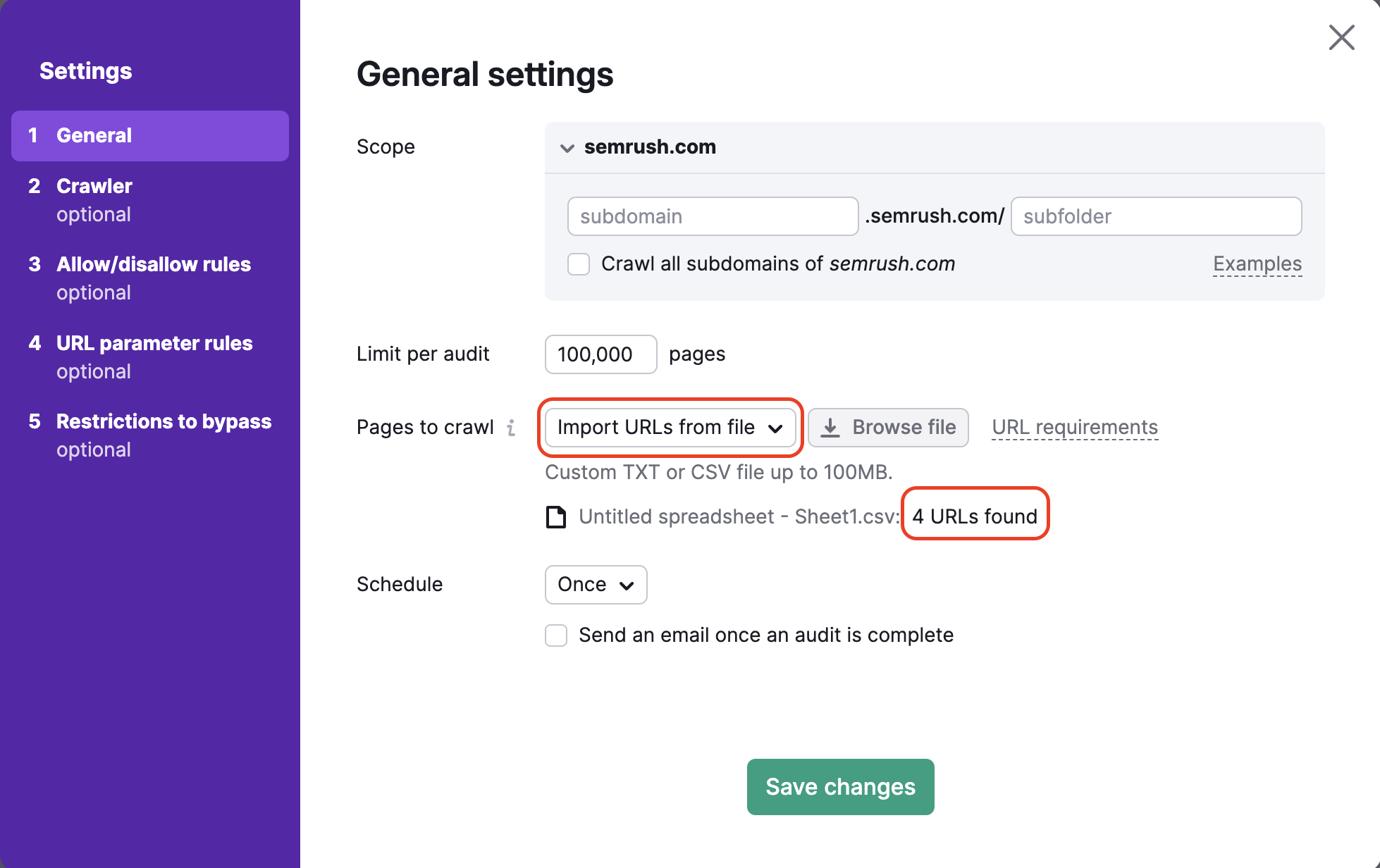
4. Beim Crawling aus einer Datei mit URLs können Sie eine besonders spezifische Gruppe von Seiten auf einer Website prüfen. Achten Sie darauf, dass Ihre Datei als .csv oder .txt mit einer URL pro Zeile formatiert ist. Laden Sie sie direkt von Ihrem Computer in Semrush hoch.
Dies ist eine nützliche Methode, falls Sie bestimmte Seiten überprüfen und Ihr Crawl-Budget schonen möchten. Wenn Sie nur eine kleine Anzahl von Seiten auf Ihrer Website geändert haben, die Sie überprüfen möchten, können Sie mit dieser Methode ein sehr spezifisches Audit durchführen, ohne Crawl-Budget zu verschwenden.
Nach dem Hochladen Ihrer Datei wird Ihnen der Assistent mitteilen, wie viele URLs erkannt wurden. So können Sie vor der Ausführung des Audits überprüfen, ob alles ordnungsgemäß funktioniert hat.
Planen
Schließlich können Sie noch auswählen, wie häufig wir Ihre Website automatisch überprüfen sollen. Ihre Optionen sind:
- Wöchentlich (wählen Sie einen beliebigen Wochentag aus)
- Täglich
- Einmal
Sie können das Audit zu jedem gewünschten Zeitpunkt erneut durchführen.
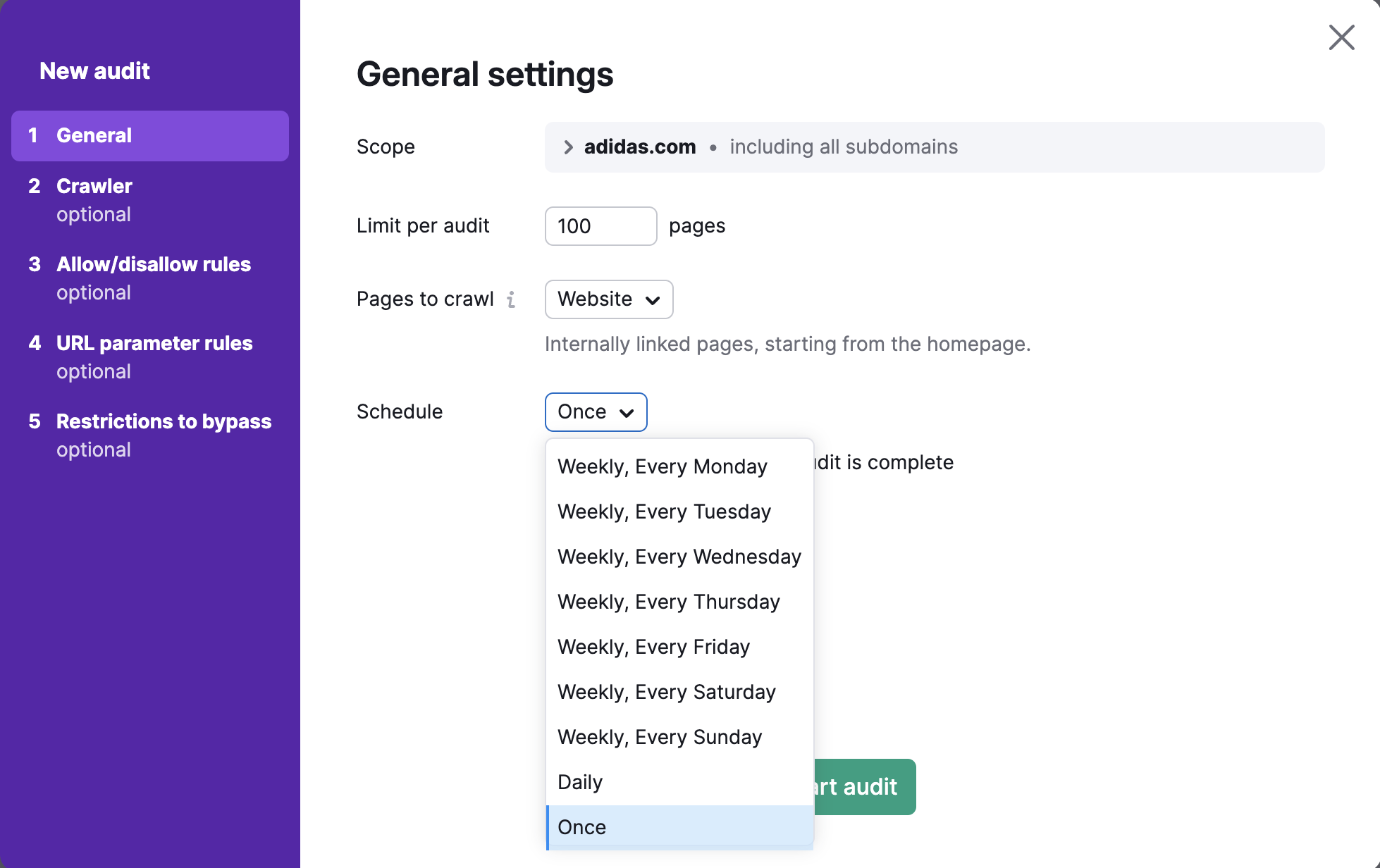
Nachdem Sie alle gewünschten Einstellungen vorgenommen haben, wählen Sie „Audit starten.“
Erweiterte Einrichtung und Konfiguration
Hinweis: Die folgenden Schritte der Konfiguration sind fortgeschritten und optional.
Crawler-Einstellungen
Hier können Sie den User Agent auswählen, mit dem Sie Ihre Website crawlen möchten. Legen Sie zunächst den User Agent für Ihr Audit fest. Wählen Sie zwischen der Mobil- oder Desktop-Version des SiteAuditBot oder des GoogleBot. Sie können auch den User Agent OpenAI-Search auswählen, der überprüft, ob Ihre Website durch den neuen Suchmaschinen-Bot crawlbar ist.
Standardmäßig überprüfen wir Ihre Website mit unserem Crawling-Bot für Mobil-Seiten, der Ihre Website auf die gleiche Weise überprüft, wie der Crawler für Mobil-Seiten von Google Ihre Website überprüfen würde. Sie können den Bot jederzeit auf den Semrush Desktop Crawler ändern.
Wenn Sie den User Agent ändern, wird sich auch der Code im Dialogfeld unten ändern. Dies ist der Code des User Agents. Er kann in einem Curl verwendet werden, falls Sie den User Agent selbst testen möchten.
Optionen zur Crawl-Verzögerung
Als Nächstes haben Sie 3 Optionen zum Festlegen einer Crawl-Verzögerung: Mindestverzögerung, robots.txt beachten und 1 URL pro 2 Sekunden.
Falls Sie diese Mindestverzögerung zwischen den Seiten aktiviert lassen, crawlt der Bot Ihre Website mit seiner normalen Geschwindigkeit. Standardmäßig wartet SiteAuditBot vor dem Crawl einer weiteren Seite etwa eine Sekunde.
Wenn Sie eine robots.txt Datei auf Ihrer Website und eine Crawl-Verzögerung angegeben haben, können Sie die Option „robots.txt beachten“ auswählen. Dann wird unser Site Audit Crawler der hier angegebenen Verzögerung folgen.
Unten sehen Sie, wie eine Crawl-Verzögerung in einer robots.txt-Datei aussehen würde:
Crawl-delay: 20
Wenn unser Crawler Ihre Website langsamer macht und Sie keine Direktive zur Crawl-Verzögerung in Ihrer robots.txt-Datei angegeben haben, können Sie Semrush anweisen, 1 URL alle 2 Sekunden zu crawlen. Dies kann dazu führen, dass es länger dauert, bis Ihr Audit abgeschlossen ist. Es wird jedoch weniger potenzielle Geschwindigkeitsprobleme für echte Benutzer auf Ihrer Website während des Audits verursachen.
JavaScript crawlen
Wenn Sie JavaScript auf Ihrer Website verwenden, können Sie JS-Rendering in den Einstellungen Ihrer Site Audit-Kampagne aktivieren. Das JavaScript-Rendering ermöglicht unserem Crawler, JS-Dateien auszuführen und die gleichen Inhalte zu sehen, die Ihre Besucher zu Gesicht bekommen. So erhalten Sie genauere Crawling-Ergebnisse (sehr ähnlich wie beim Googlebot) und ein besseres Bild vom technischen Zustand Ihrer Website.
Wenn das JS-Rendering deaktiviert ist, betrachtet Site Audit nur das HTML Ihrer Website. Das Crawlen von HTML ist zwar schneller ist und macht Ihre Website nicht langsamer. Allerdings sind die Ergebnisse des Audits weniger genau.

Bitte beachten Sie, dass diese Funktion nur mit einem Guru- oder Business-Abonnement für das SEO Toolkit verfügbar ist.
Allow-/Disallow-Regeln
Um bestimmte Unterordner einer Website zu crawlen oder sie zu blockieren, führen Sie beim Einrichten von Site Audit den Schritt „URLs zulassen/verbieten“ durch. Dieser Schritt ermöglicht auch Audits mehrerer bestimmter Unterordner gleichzeitig.
Schließen Sie in folgendem Textfeld alles innerhalb der URL nach der TLD ein. Wenn Sie zum Beispiel den Unterordner http://www.example.com/shoes/mens/ crawlen möchten, müssten Sie „/shoes/mens/“ in das Feld für erlaubte Urls auf der linken Seite eingeben.
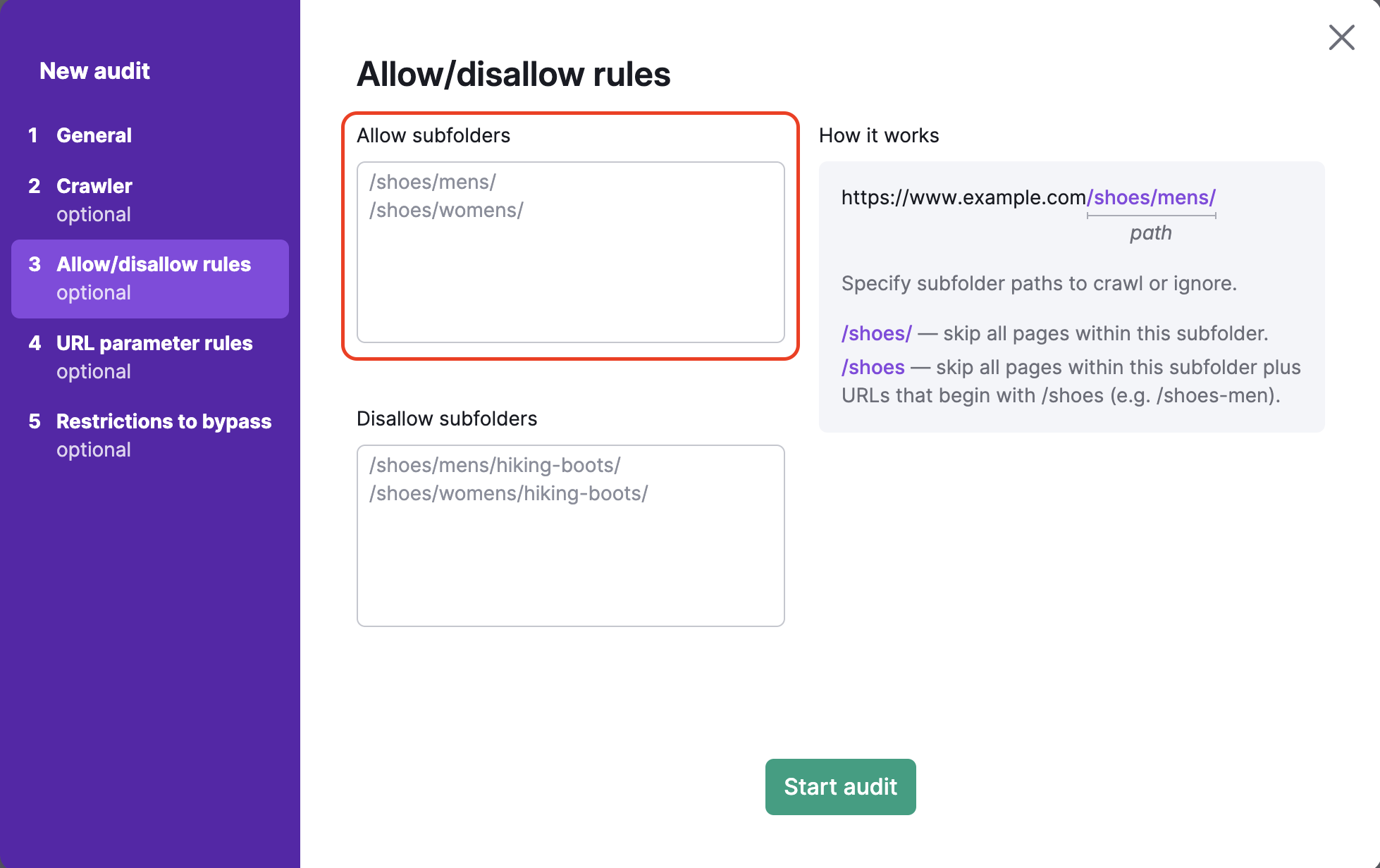
Um zu verhindern, dass bestimmte Unterordner gecrawlt werden, müssen Sie den Pfad des Unterordners in das Feld für nicht zugelassene URLs eingeben. Um beispielsweise die Kategorie der Herrenschuhe zu crawlen, aber die Unterkategorie der Wanderschuhe unter den Herrenschuhen auszuschließen (https://example.com/shoes/mens/hiking-boots/), würden Sie /shoes/mens/hiking-boots/ in das Disallow-Feld eingeben.
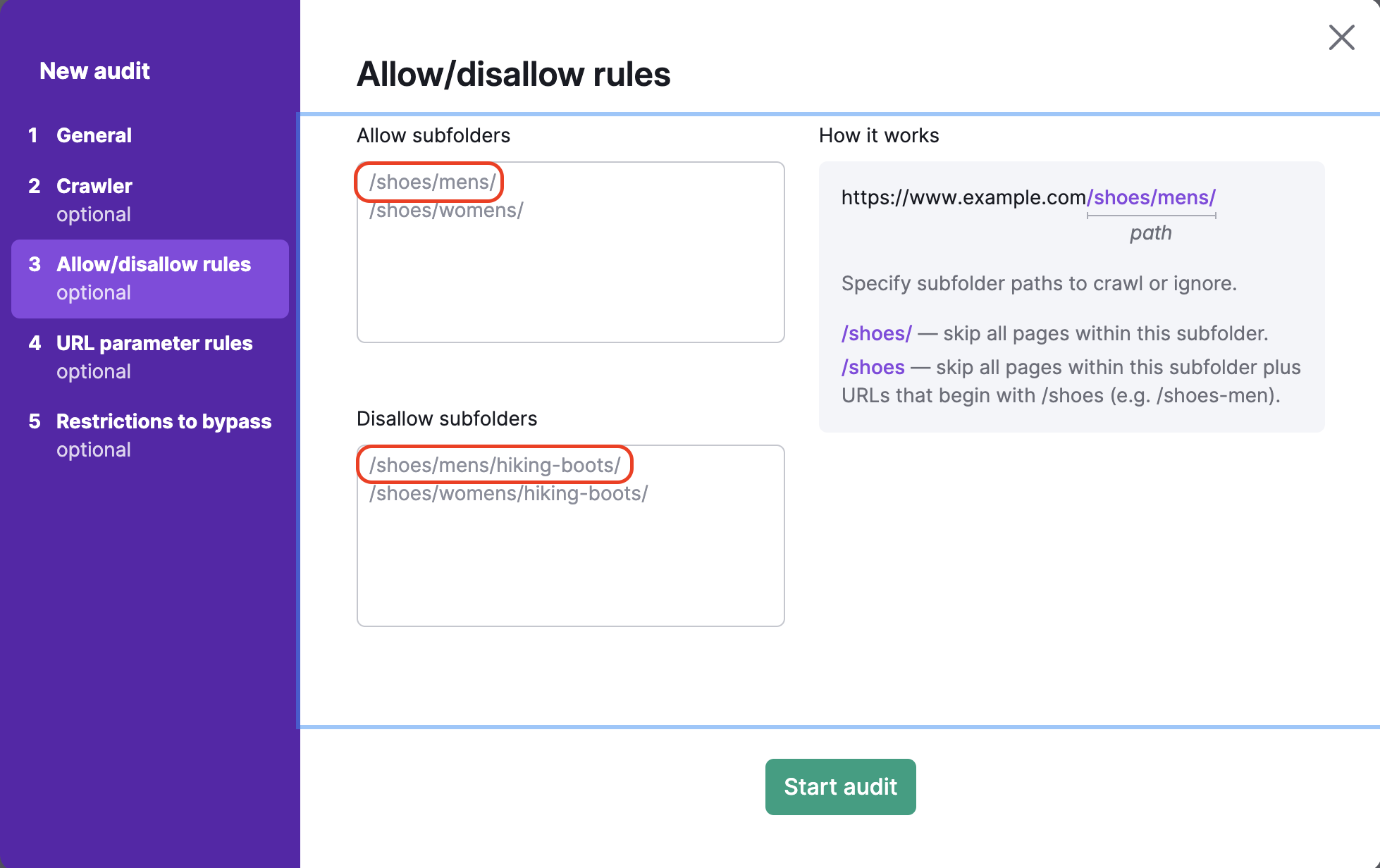
Wenn Sie vergessen, den Schrägstrich / am Ende der URL im Disallow-Feld einzugeben (z.B.: /shoes), dann wird Semrush alle Seiten im Unterordner /shoes/ sowie alle URLs, die mit /shoes beginnen (wie www.example.com/shoes-men), überspringen.
URL-Parameter-Regeln
URL-Parameter (auch bekannt als Query-Strings) sind Elemente einer URL, die nicht zur hierarchischen Pfadstruktur gehören. Stattdessen werden sie am Ende einer URL angehängt und geben dem Webbrowser logische Anweisungen.
URL-Parameter beginnen immer mit einem „?“, gefolgt von dem Parameternamen (page, utm_medium, etc.) und „=“.
„?page=3“ ist also ein einfacher URL-Parameter, der die dritte Seite beim Blättern auf einer einzelnen URL anzeigen kann.
Im vierten Schritt der Konfiguration von Site Audit können Sie alle URL-Parameter angeben, die Ihre Website verwendet, um sie beim Crawlen aus den URLs zu entfernen. So können Sie verhindern, dass Semrush dieselbe Seite während Ihres Audits zweimal crawlt. Wenn ein Bot zwei URLs sieht – eine mit einem Parameter und eine ohne – kann es sein, dass er beide Seiten crawlt und dadurch Ihr Crawl-Budget verschwendet.
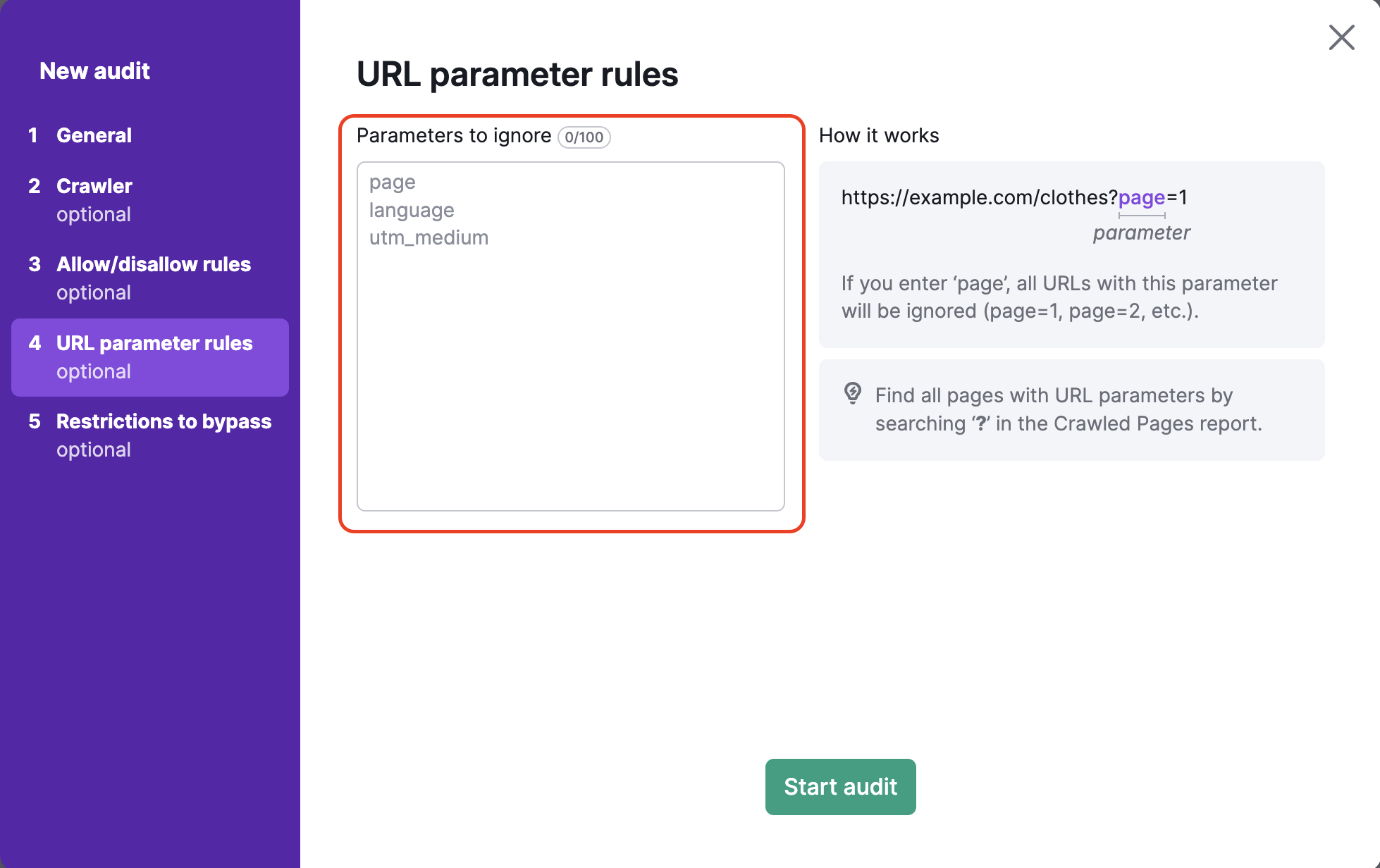
Wenn Sie zum Beispiel „page“ in dieses Feld eintragen, werden alle URLs entfernt, die „page“ in der URL-Erweiterung enthalten. Das wären URLs mit Werten wie ?page=1, ?page=2 usw. So wird verhindert, dass dieselbe Seite zweimal gecrawlt wird (z. B. sowohl „/shoes“ als auch „/shoes/?page=1“ als eine URL).
URL-Parameter werden häufig für Seiten, Sprachen und Unterkategorien verwendet. Diese Arten von Parametern sind nützlich für Websites mit großen Produkt- oder Informationskatalogen. Ein weiterer gängiger URL-Parametertyp sind UTMs. Sie werden zum Tracking von Klicks und Traffic aus Marketingkampagnen verwendet.
Falls Sie bereits eine Kampagne in Site Audit eingerichtet haben und Ihre Einstellungen ändern möchten, können Sie dies über die Einstellungen tun, die Sie über das Zahnrad-Symbol erreichen:
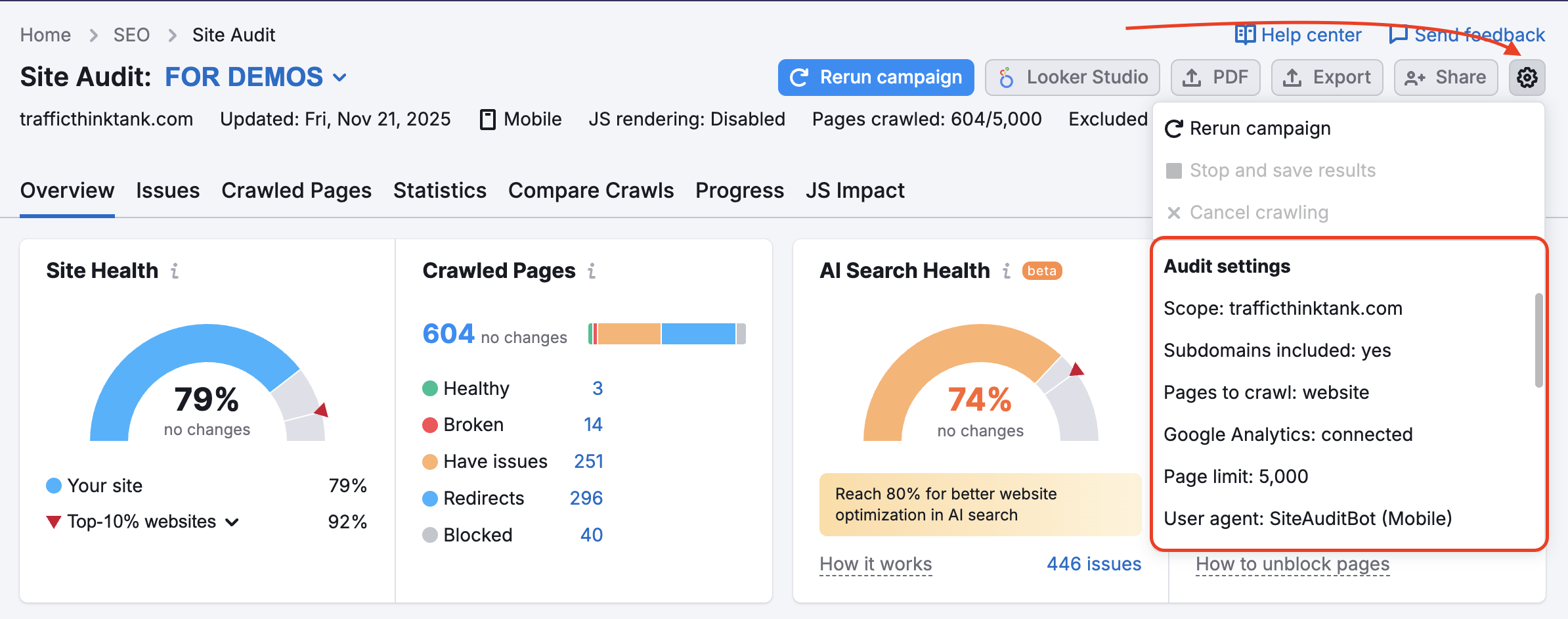
Sie gehen wie oben beschrieben vor und wählen die Optionen „Masken“ und „Entfernte Parameter“ aus.
Zu umgehende Einschränkungen
Um eine Website zu prüfen, die noch nicht live oder hinter einer Basisauthentifizierung verborgen ist, bietet Schritt 5 drei Möglichkeiten:


Umgehen der Disallow-Direktive in der robots.txt-Datei und dem robots-Meta-Tag
Wenn Sie die Disallow-Direktiven in der robots.txt-Datei oder im Meta-Tag umgehen möchten (normalerweise finden Sie diesen innerhalb des Head-Elements Ihrer Website), müssen Sie die von Semrush bereitgestellte Datei in den Hauptordner Ihrer Website hochladen.
Wenn Sie die Disallow-Direktiven in der robots.txt-Datei oder im Meta-Tag umgehen möchten (normalerweise finden Sie diesen innerhalb des Head-Elements Ihrer Website), müssen Sie die von Semrush bereitgestellte Datei in den Hauptordner Ihrer Website hochladen. Dieser Vorgang überprüft, ob Sie Inhaber sind, und ermöglicht unserem Bot, die Website zu crawlen.Crawlen mit Ihren Anmeldedaten
Dies wird für nicht-öffentliche Websites oder solche, die sich noch in der Entwicklung befinden, empfohlen. Geben Sie einfach den Benutzernamen und das Kennwort ein, die Sie zum Zugriff auf den verborgenen Bereich Ihrer Website verwenden. Unser Bot wird diese Anmeldedaten verwenden, um den Kennwortschutz dieser Bereiche zu umgehen und Ihre Audit-Ergebnisse bereitzustellen.
Mit Web Bot Auth-Signatur crawlen
Einige Hosting-Plattformen wie Shopify sperren aus Sicherheits- oder Performance-Gründen möglicherweise standardmäßig unbekannte Bots aus. Das Hinzufügen einer Web Bot Auth-Signatur ermöglicht dem Semrush-Crawler, sich zu identifizieren und nachzuweisen, dass er zum Zugriff auf Ihre Website berechtigt ist.
So richten Sie das ein:
- Aktivieren Sie das Kontrollkästchen Mit Web Bot Auth-Signatur crawlen.
- Signatur-Agent: Geben Sie die Agent-URL ein (z. B. "https://shopify.com").
- Signatur-Eingabe: Geben Sie die vom Host geforderte spezifische Eingabezeichenfolge ein.
- Signatur: Geben Sie die eindeutige, verschlüsselte Signatur ein, die von Ihrer Plattform bereitgestellt wurde.
Problembehebung
Falls die Meldung „Fehler beim Audit von [Domain]“ erscheint, sollten Sie sicherstellen, das unser Site Audit-Crawler nicht von Ihrem Server blockiert wird. Um einen ordnungsgemäßen Crawl zu gewährleisten, befolgen Sie bitte unsere Schritte unter Fehlerbehebung bei Site Audit, damit unser Bot auf die Whitelist gesetzt wird.
Alternativ können Sie die Protokolldatei herunterladen, die beim fehlgeschlagenen Crawl erstellt wurde, und sie Ihrem Webmaster zur Verfügung stellen. Er kann dann die Situation analysieren und versuchen, einen Grund dafür zu finden, weshalb wir beim Crawlen ausgesperrt werden.
So verknüpfen Sie Google Analytics mit Site Audit
Nachdem Sie den Einrichtungsassistenten abgeschlossen haben, können Sie Ihr Google Analytics-Konto verbinden, um Probleme einzuschließen, die in Zusammenhang mit Ihren am häufigsten aufgerufenen Seiten auftreten.
Falls bei Ihrem Site Audit weiterhin Probleme auftreten, versuchen Sie, unter Fehlerbehebung bei Site Audit eine Lösung zu finden.